第 6 章 R Markdown 的操作技巧
6.1 表格操作进阶
在日常报告中,表格是展示结果的主要方式之一,例如下表展示了某中学某次考试的学生成绩:
grade <- data.frame(
姓名 = c("张三", "李四", "王五"),
语文 = c(89, 90, 85),
数学 = c(93, 97, 91),
英语 = c(92, 85, 97)
)
knitr::kable(grade)| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
读者可以通过 knitr::kable() 函数的各项参数调整默认的表格外观,例如 align 参数可以调整表格的对齐方式,caption 参数可以添加表格的标题,一个改进版如表 6.1 所示:
knitr::kable(grade, align='cccc', caption = '考试成绩')| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
除了居中操作以及添加标题外,在制作表格时还会产生各种各样的特定需求,例如合并单元格、添加底色等。本节将系统地介绍在 R Markdown 中生成表格和进一步对其个性化的方法,主要包括下列内容:
介绍
knitr::kable()的用法和主要参数;使用 kableExtra (Zhu 2021) 包扩展表格样式
提供其它生成表格的 R 包以供读者参考
6.1.1 利用函数 knitr::kable() 生成复杂的表格
在 R Markdown 中,通常使用 knitr 包中的函数 kable() 来快速创建一个表格。kable() 可以处理数据框、矩阵等“矩形数据”,快速生成表格,而表格的外观则可以通过修改函数参数来自定义,下面将对这些参数进行介绍:
kable(x, format, digits = getOption("digits"),
row.names = NA, col.names = NA, align, caption = NULL,
label = NULL, format.args = list(), escape = TRUE,
...)6.1.1.1 表格样式
在大多数情况下,如果只需要制作一个简单表格,knitr::kable(x) 就足够了。其中第二个参数 format 会根据输出格式自动设置。它可能的取值是 pipe(列与列之间由短的竖线分隔的表),simple (仅包含横向分割线的简单表格),latex (LaTex 表格),html (HTML 表格),和 rst (reStructuredText 表格)。为了展示各个取值的不同,这里直接给出了各个取值在不同编程语言中的原始代码。
对于 R Markdown 文档,kable() 默认使用 pipe 格式的表格,输出结果如下所示:
knitr::kable(grade, 'pipe')| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
knitr::kable() 也可以生成一个(基于 Pandoc 的)简单的表格,或 HMTL、LaTex 以及 reStructuredText 格式的表格:
knitr::kable(grade, 'simple')姓名 语文 数学 英语
----- ----- ----- -----
张三 89 93 92
李四 90 97 85
王五 85 91 97knitr::kable(grade, 'html')<table>
<thead>
<tr>
<th style="text-align:left;"> 姓名 </th>
<th style="text-align:right;"> 语文 </th>
<th style="text-align:right;"> 数学 </th>
<th style="text-align:right;"> 英语 </th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align:left;"> 张三 </td>
<td style="text-align:right;"> 89 </td>
<td style="text-align:right;"> 93 </td>
<td style="text-align:right;"> 92 </td>
</tr>
<tr>
<td style="text-align:left;"> 李四 </td>
<td style="text-align:right;"> 90 </td>
<td style="text-align:right;"> 97 </td>
<td style="text-align:right;"> 85 </td>
</tr>
<tr>
<td style="text-align:left;"> 王五 </td>
<td style="text-align:right;"> 85 </td>
<td style="text-align:right;"> 91 </td>
<td style="text-align:right;"> 97 </td>
</tr>
</tbody>
</table>knitr::kable(grade, 'latex')\begin{tabular}{l|r|r|r}
\hline
姓名 & 语文 & 数学 & 英语\\
\hline
张三 & 89 & 93 & 92\\
\hline
李四 & 90 & 97 & 85\\
\hline
王五 & 85 & 91 & 97\\
\hline
\end{tabular}knitr::kable(grade, 'rst')==== ==== ==== ====
姓名 语文 数学 英语
==== ==== ==== ====
张三 89 93 92
李四 90 97 85
王五 85 91 97
==== ==== ==== ====需要注意的是,只有 pipe 和 simple 格式是“可移植”的,也就是说,它们适用于任何输出文档的格式,而其他格式则只适用于特定的输出格式,例如,format = 'latex' 只适用于 LaTeX 输出文档。使用特定的表格格式可以带来更多的自主控制能力,但代价是牺牲了可移植性。
如果想要为文档中的所有表格统一设置格式,可以使用选项 knitr.table.format。例如若只需要 LaTeX 格式的表格,则可以设置:
options(knitr.table.format = 'latex')knitr.table.format 还可以接受一个函数处理更复杂的条件逻辑。例如,只在输出格式为 LaTeX 时使用 latex 格式:
options(knitr.table.format = function() {
if (knitr::is_latex_output()) 'latex' else 'pipe'
})如果函数返回 NULL,knitr 将自动决定适当的格式。
6.1.1.2 修改列名
在一些情况下,在数据框(data frame)中定义的列的名称可能与想要显示给读者的内容不同,需要进行修改。在使用英文时,数据的列名通常不使用空格来分隔单词,而是使用点、下划线以及大小写来进行分隔。而在制作表格时,这样的变量名会显得有些不自然。在中文环境下,虽然空格的问题较少,但也存在变量名过长的情况,在 R 中也往往使用简化的名词或对应的英文简写来代替。在这种情况下,可以使用 col.names 参数将列名替换为一个包含新名称的向量,即 col.names = c(...)。例如,可以在上文成绩表的列名中提供更多信息:
knitr::kable(
grade,
col.names = c(paste0('第1组', colnames(grade)))
)| 第1组姓名 | 第1组语文 | 第1组数学 | 第1组英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
col.names 参数可以接受任意的字符向量(不一定是通过 paste0() 等函数修改的列名),只要向量的长度等于数据对象的列数即可,例如可以把列名换成英文:
knitr::kable(
grade,
col.names = c('Name', 'Chinese', 'Math', 'English')
)| Name | Chinese | Math | English |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
6.1.1.3 指定列的对齐方式
如果想要改变表格中列的对齐方式,可以使用由字符 l (left,左对齐)、c (center,居中)以及 r (right,右对齐)组成的值向量或一个多字符的字符串来进行对齐,即 kable(..., align = c('c', 'l')) 和 kable(..., align = 'cl') 是等价的。在默认情况下,数字列是右对齐的,其他列是左对齐的。例如可以对成绩表进行调整,使得前两列右对齐,后两列左对齐:
knitr::kable(grade, align = 'rrll')| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
而当对齐方式统一时,也可以用一个字母来代替,例如可以把成绩表所有列都居中表示:
knitr::kable(grade, align = 'c')| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
6.1.1.4 添加表格标题
给表格添加标题需要用到 caption 参数,如表 6.2 所示:
knitr::kable(grade, caption = '考试成绩')| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
正如本书 2.8.7 节所提到的那样,当一个表格有标题并且以 bookdown 来输出格式时,它可以被交叉引用,而在基础的 html_document 和 pdf_document 中则不行。
6.1.1.5 调整数字格式
有的时候,表格中的数字位数很长,展示的时候需要缩短,这时可以通过 digits 参数(会被传递给 round() 函数)来设置最大的小数位数,以及通过 format.args(会被传递给 R 中的 format() 函数)来设置其他格式化参数。
首先是几个简单的 round() 和 format() 的例子,从而可以更好地理解之后的 kable() 中 digits 参数是如何工作的:
round(1.234567, 0)
## [1] 1
round(1.234567, digits = 1)
## [1] 1.2
round(1.234567, digits = 3)
## [1] 1.235
format(1000, scientific = TRUE)
## [1] "1e+03"
format(10000.123, big.mark = ',')
## [1] "10,000.12"可以将数字四舍五入并格式化成表格:
d = cbind(
X1 = runif(3),
X2 = 10^c(3, 5, 7),
X3 = rnorm(3, 0, 1000)
)
# 保留最多四位小数
knitr::kable(d, digits = 4)| X1 | X2 | X3 |
|---|---|---|
| 0.4513 | 1e+03 | -300.9029 |
| 0.7838 | 1e+05 | 528.2758 |
| 0.7097 | 1e+07 | -622.8860 |
# 每列分别设置
knitr::kable(d, digits = c(5, 0, 2))| X1 | X2 | X3 |
|---|---|---|
| 0.45127 | 1e+03 | -300.90 |
| 0.78378 | 1e+05 | 528.28 |
| 0.70968 | 1e+07 | -622.89 |
# 不使用科学计数法
knitr::kable(
d,
digits = 3,
format.args = list(scientific = FALSE)
)| X1 | X2 | X3 |
|---|---|---|
| 0.451 | 1000 | -300.903 |
| 0.784 | 100000 | 528.276 |
| 0.710 | 10000000 | -622.886 |
# 给 big numbers 添加逗号
knitr::kable(
d,
digits = 3,
format.args = list(big.mark = ',', scientific = FALSE)
)| X1 | X2 | X3 |
|---|---|---|
| 0.451 | 1,000 | -300.903 |
| 0.784 | 100,000 | 528.276 |
| 0.710 | 10,000,000 | -622.886 |
6.1.1.6 显示缺失值
表中可能存在缺失值,如该学生没有缺考或没有选修某个课。在默认情况下,R 中缺失值(如NA)在表格中显示为字符串NA,如:
grade2 <- data.frame(姓名 = c("张三","李四","王五"),
物理 = c(NA,90,85),
政治 = c(93,97,NA),
计算机 = c(92,NA,97))
knitr::kable(grade2) # 默认显示 NA| 姓名 | 物理 | 政治 | 计算机 |
|---|---|---|---|
| 张三 | NA | 93 | 92 |
| 李四 | 90 | 97 | NA |
| 王五 | 85 | NA | 97 |
为了使表格美观,也可以使用其他的值来替换它们,或者通过使用全局 R 选项 knitr.kable.NA 来调整显示的内容(例如使 NA 对应的单元格为空)。例如,可以将下面第一个表中的 NA 单元格设为空,然后在第二个表中显示 **:
# 用空值代替 NA
opts <- options(knitr.kable.NA = '')
knitr::kable(grade2)| 姓名 | 物理 | 政治 | 计算机 |
|---|---|---|---|
| 张三 | 93 | 92 | |
| 李四 | 90 | 97 | |
| 王五 | 85 | 97 |
# 用指定字符(**) 代替 NA
options(knitr.kable.NA = '**')
knitr::kable(grade2)| 姓名 | 物理 | 政治 | 计算机 |
|---|---|---|---|
| 张三 | ** | 93 | 92 |
| 李四 | 90 | 97 | ** |
| 王五 | 85 | ** | 97 |
options(opts) # 恢复全局 R 选项6.1.1.7 转义特殊字符
HTML 和 LaTeX 中都包含了特殊字符,它们不显示为文本,而代表特定的格式,例如 HTML 里的   和 LaTeX 里的 $ 等。当表格文本包含这些特殊字符时,kable() 将默认通过参数 escape = TRUE 来 转义这些特殊字符,即令这些特殊字符失去其特殊含义,显示文本本身(如 \beta 将不会自动显示为 \(\beta\))。例如对于 HTML 格式的表格,> 将被替换为 >;而对于 LaTeX 格式的表格,_ 将被转义为 \_ 26。
如果需要特殊字符代表的格式,可以用 escape = FALSE 禁用转义,但要注意确保特殊字符不会在 LaTeX 或 HTML 中触发语法错误。表 6.3 展示了转义之后的结果,表 6.4 则展示了一些包含特殊字符($、\ 以及 _)的 LaTeX 数学表达式:
# 添加数学表达式
g_range <- data.frame(
成绩范围 = c("$\\ge 90$","$\\ge 80$", "$\\ge 70$"),
语文 = c(6,10,20),
数学 = c(3,7,16),
英语 = c(5,15,20)
)
colnames(g_range) <- c("成绩范围", "$Chinese_{Jan}$", "$Math_{Jan}$", "$English_{Jan}$")
knitr::kable(
g_range,
escape = TRUE,
caption = "escape = TRUE 生成的表"
)| 成绩范围 | \(Chinese_{Jan}\) | \(Math_{Jan}\) | \(English_{Jan}\) |
|---|---|---|---|
| \(\ge 90\) | 6 | 3 | 5 |
| \(\ge 80\) | 10 | 7 | 15 |
| \(\ge 70\) | 20 | 16 | 20 |
knitr::kable(
g_range,
escape = FALSE,
caption = "escape = FALSE 生成的表"
)| 成绩范围 | \(Chinese_{Jan}\) | \(Math_{Jan}\) | \(English_{Jan}\) |
|---|---|---|---|
| \(\ge 90\) | 6 | 3 | 5 |
| \(\ge 80\) | 10 | 7 | 15 |
| \(\ge 70\) | 20 | 16 | 20 |
如表 6.3 所示,如果设置 escape = TRUE,特殊字符将被转义或替换。例如,在 LaTeX 格式的表格中,$ 会被转义为 \$、_ 被转义为 \_ 以及 \ 被替换为 \textbackslash{}:
knitr::kable(g_range[,1:2], format = 'latex', escape = TRUE)\begin{tabular}{l|r}
\hline
成绩范围 & \$Chinese\_\{Jan\}\$\\
\hline
\$\textbackslash{}ge 90\$ & 6\\
\hline
\$\textbackslash{}ge 80\$ & 10\\
\hline
\$\textbackslash{}ge 70\$ & 20\\
\hline
\end{tabular}其他 LaTeX 中常见的特殊字符包括 #、%、&、{ 以及 };HTML 中常见的特殊字符包括 &、<、 > 以及 "。在生成带有 escape = FALSE 的表格时,需要格外小心并确保正确地使用了特殊字符。一个常见的错误是在使用 escape = FALSE 时,在 LaTeX 表格的列名或标题中包含 % 或 _ 等字符,而没有意识到它们是特殊的字符。
如果想知道 escape = TRUE 参数会如何转义特殊字符,可以通过 knitr 中两个内部辅助函数 escape_latex 和 escape_html 来分别查询在 LaTeX 和 HTML 格式的表格中的转义结果:。下面是一些例子:
knitr:::escape_latex(c('100%', '# 一个观点', '文字_1'))## [1] "100\\%" "\\# 一个观点" "文字\\_1"knitr:::escape_html(c('<address>', 'x = "字符"', 'a & b'))## [1] "<address>" "x = "字符"" "a & b"6.1.1.8 并排多张表格
当 kable() 的第一个参数是包含多个数据框的列表时,它会生成多个并排放置的表格。例如,表 6.5 包含了之前展示过的两张表:
# 数据对象 grade 和 grade2 由之前的代码块生成
knitr::kable(
list(grade, grade2),
caption = '两张表并排放置',
booktabs = TRUE, valign = 't'
)
|
|
需要注意的是,此功能仅适用于 HTML 和 PDF 格式的输出。
另外,如果在并排放置各个表的时候,想能够分别自定义它们,可以使用 kables() 函数(即 kable() 的复数形式),并将一个对象为 kable() 的列表传递给它。例如,在表 6.6 中,可以更改左表中的列名,并将右表中的小数点位数设置为 4:
# 数据对象 grade 和 d 由之前的代码块生成
knitr::kables(
list(
# 第一个 kable():修改列名
knitr::kable(
grade,
col.names = c('Name', 'Chinese', 'Math', 'English'),
valign = 't'
),
# 第二个 kable():设置 digits 选项
knitr::kable(d, digits = 4, valign = 't')
),
caption = '由 knitr::kables() 生成的两张表'
)
|
|
6.1.1.9 利用 for 循环生成多个表 (*)
结合 for 循环与 kable() 生成多张表时,有一点需要额外注意。必须在迭代中用 print() 显示打印 kable() 的结果,并应用块选项 results = 'asis',例如:
```{r, results='asis'}
for (i in 1:3) {
print(knitr::kable(grade))
}
```而下面的代码块只会在文档中输出最后一张表:
```{r}
for (i in 1:3) {
knitr::kable(grade)
}
```这个问题并不特定于 kable(),同时也存在于许多其他的 R 包中。其背后原因较为复杂,对技术细节感兴趣的读者可以参考博文 “The Ghost Printer behind Top-level R Expressions.”
需要生成多个表格时,最好添加一些换行符(\n)或 HTML 注释(<!-- -->),从而清晰地分隔所有输出的元素,例如:
```{r, results='asis'}
for (i in 1:3) {
print(knitr::kable(grade, caption = '标题'))
cat('\n\n<!-- -->\n\n')
}
```如果没有这些分隔符,Pandoc 可能无法检测到某些元素。例如,当一个图片之后面紧跟着一个表格时,这个表格并不会被识别到:

姓名 语文 数学 英语
----- ----- ----- -----
张三 89 93 92
李四 90 97 85
王五 85 91 97解决办法是用空行或注释分隔图片和表格,例如:

姓名 语文 数学 英语
----- ----- ----- -----
张三 89 93 92
李四 90 97 85
王五 85 91 97或者:

<!-- -->
姓名 语文 数学 英语
----- ----- ----- -----
张三 89 93 92
李四 90 97 85
王五 85 91 976.1.1.10 自定义 LaTeX 表格 (*)
如果只需要 LaTeX 格式的输出时,可以在 kable() 中使用一些额外的选项。注意在其他类型的输出中(如 HTML),这些选项将被忽略。除非已经设置了全局的表格格式选项(见本书 6.1.1.1 节),否则必须像本节的例子那样使用 kable() 的 format 参数,例如:
knitr::kable(grade, format = 'latex', booktabs = TRUE)带标题的表格(见本书 6.1.1.4 节)会被放入 table 环境中,即:
\begin{table}
% 表格 (通常为 tabular 环境)
\end{table}不同的环境有不同的默认排版方式,例如 LaTeX 会对 table 及 figure 等环境采用浮动布局。可以通过 table.envir 参数来对环境进行调整:
knitr::kable(grade, format = 'latex', table.envir = 'Table')\begin{Table}
\begin{tabular}{l|r|r|r}
\hline
姓名 & 语文 & 数学 & 英语\\
\hline
张三 & 89 & 93 & 92\\
\hline
李四 & 90 & 97 & 85\\
\hline
王五 & 85 & 91 & 97\\
\hline
\end{tabular}
\end{Table}表格的位置由参数 position 来控制。例如,可以通过 position = "!b" 来强制将表格固定到页面的底部:
knitr::kable(grade, format = 'latex',
table.envir = 'table', position = '!b')\begin{table}[!b]
\begin{tabular}{l|r|r|r}
\hline
姓名 & 语文 & 数学 & 英语\\
\hline
张三 & 89 & 93 & 92\\
\hline
李四 & 90 & 97 & 85\\
\hline
王五 & 85 & 91 & 97\\
\hline
\end{tabular}
\end{table}当表格有标题时,也可以通过 caption.short 参数给它分配一个短的标题,例如:
knitr::kable(grade, caption = '一个很长很长的标题!',
caption.short = '短标题')短标题将会进入 LaTeX 中 \caption[]{} 命令的方括号中,经常在 PDF 输出文档的表格目录中使用(如果不提供短标题,那里则会显示完整的标题)。
booktabs = TRUE 可以使用 LaTeX 包 booktabs{LaTeX package!booktabs} 进行表格排版。
knitr::kable(grade, format = 'latex', booktabs = TRUE)\begin{tabular}{lrrr}
\toprule
姓名 & 语文 & 数学 & 英语\\
\midrule
张三 & 89 & 93 & 92\\
李四 & 90 & 97 & 85\\
王五 & 85 & 91 & 97\\
\bottomrule
\end{tabular}需要注意的是,当在 R Markdown 文档中需要额外的 LaTeX 包时(如 booktabs),必须在 YAML 中声明这些包(请参阅第 3.2.4 节了解如何声明):
```{r booktabs-false, include=knitr::is_latex_output()}
knitr::kable(grade, format = 'latex',
booktabs = FALSE,
caption = 'booktabs = FALSE 时的表格')
```
```{r booktabs-true, include=knitr::is_latex_output()}
knitr::kable(grade, format = 'latex',
booktabs = TRUE,
caption = 'booktabs = TRUE 时的表格')
```
图 6.1: booktabs 表格样式
对于 booktabs = FALSE:
表的列由垂直线分隔。可以通过
vline参数来删除垂直线,例如knitr::kable(grade, vline = "")(默认值是vline = "|")。也可以将这个选项设置为一个全局的 R 选项,这样就不需要为每个表设置它,例如options(knitr.table.vline = "")。水平线可以通过参数
toprule、midrule、linesep以及bottomrule来定义,它们的默认值都是\hline。
对于 booktabs = TRUE:
表格中没有垂直线,但可以通过
vline参数来添加。表格只有标题和底部行有水平线。默认参数值是
toprule = "\\toprule"、midrule = "\\midrule"以及bottomrule = "\\bottomrule"。默认情况下,每 5 行加一个行间距(\addlinespace),这是由参数linesep控制的,默认值为c("", "", "", "", "\\addlinespace")。如果想每 1 行加一个\addlinespace,则可以这样做:
knitr::kable(grade, format = 'latex',
linesep = c('\\addlinespace'),
booktabs = TRUE)\begin{tabular}{lrrr}
\toprule
姓名 & 语文 & 数学 & 英语\\
\midrule
张三 & 89 & 93 & 92\\
\addlinespace
李四 & 90 & 97 & 85\\
\addlinespace
王五 & 85 & 91 & 97\\
\bottomrule
\end{tabular}如果想删除所有的行间距,可以使用linesep = ''。
有的时候,表可能比一页还长。可以使用参数 longtable = TRUE,该参数使用 LaTeX 包 longtable 将表跨到多个页面。
另外,当表格被包含在 table 环境中时(例如,当表有标题时),表格默认居中对齐。如果不想让表格居中,可以使用参数 centering = FALSE。
6.1.1.11 自定义 HTML 表格 (*)
如果想自定义通过 knitr::kable(format = "html") 生成的表,除了前面提到的常见参数外,还有一个额外的参数需要注意:table.attr。这个参数允许用户向 <table> 标签添加任意属性。例如可以向表格中添加一个类striped:
knitr::kable(grade, table.attr = 'class="striped"',
format = "html")<table class="striped">
<thead>
<tr>
<th style="text-align:left;"> 姓名 </th>
<th style="text-align:right;"> 语文 </th>
<th style="text-align:right;"> 数学 </th>
<th style="text-align:right;"> 英语 </th>
</tr>
</thead>
<tbody>
<tr>
<td style="text-align:left;"> 张三 </td>
<td style="text-align:right;"> 89 </td>
<td style="text-align:right;"> 93 </td>
<td style="text-align:right;"> 92 </td>
</tr>
<tr>
<td style="text-align:left;"> 李四 </td>
<td style="text-align:right;"> 90 </td>
<td style="text-align:right;"> 97 </td>
<td style="text-align:right;"> 85 </td>
</tr>
<tr>
<td style="text-align:left;"> 王五 </td>
<td style="text-align:right;"> 85 </td>
<td style="text-align:right;"> 91 </td>
<td style="text-align:right;"> 97 </td>
</tr>
</tbody>
</table>然而,类的名称不足以改变表的外观,必须定义 CSS27 类的规则。例如,要制作奇数行和偶数行有不同颜色的条纹表,可以为偶数行或奇数行添加浅灰色背景:
.striped tr:nth-child(even) { background: #eee; }上面的 CSS 规则意味着所有 striped 类的元素的子元素,且具有偶数行号(:nth-child(even))的行(即 <tr> 标签),将它们的背景颜色设置为 #eee。
使用一点 CSS 可以使一个普通的 HTML 表看起来好看很多。图 6.2 是一个 HTML 表格的截图,其中应用了以下 CSS 规则:
table {
margin: auto;
border-top: 1px solid #666;
border-bottom: 1px solid #666;
}
table thead th { border-bottom: 1px solid #ddd; }
th, td { padding: 5px; }
thead, tfoot, tr:nth-child(even) { background: #eee; }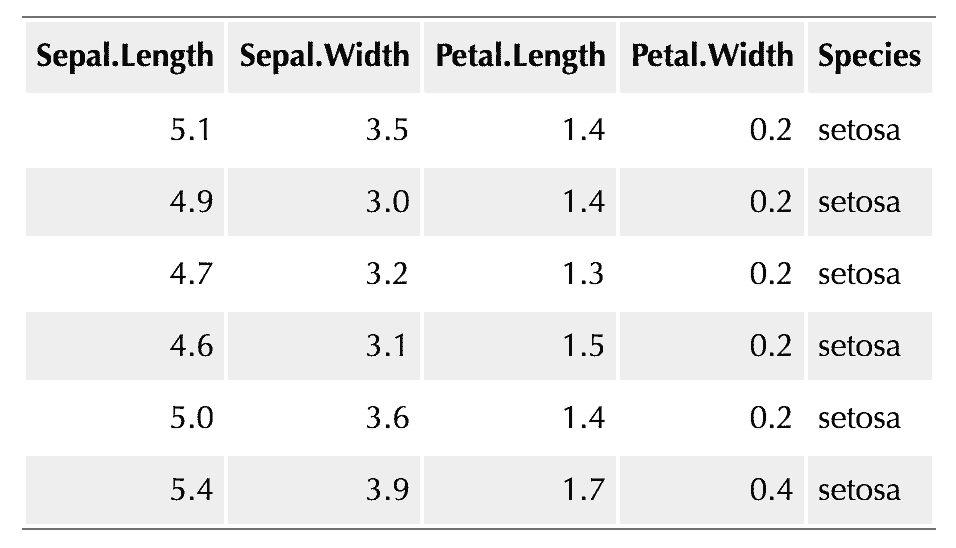
图 6.2: 利用 HTML 和 CSS 创建的条纹表
6.1.2 利用 kableExtra 美化表格
kableExtra 包(Zhu 2021) 设计的目的为扩展 knitr::kable() 生成表格的基本功能(见第 6.1.1 节)。由于 knitr::kable() 的设计很简单,就像很多其他的 R 包一样,它肯定有很多缺失的功能,而 kableExtra 完美地填补了空白,可以配合 knitr::kable() 生成更好看的表格。最令人惊讶的是,kableExtra 的大多数表格的特性都适用于 HTML 和 PDF 格式,例如,借助 kableExtra 包可以绘制如图 6.2 的条纹表。
一般情况下,kableExtra 包可以通过 CRAN 安装,也可以尝试 GitHub 上的开发版本 (https://github.com/haozhu233/kableExtra):
# 通过 CRAN 安装
install.packages("kableExtra")
# 安装开发版本
remotes::install_github("haozhu233/kableExtra")https://haozhu233.github.io/kableExtra/ 提供了大量的文档,介绍了很多关于如何自定义 kable() 的 HTML 或 LaTeX 输出结果的例子。本节只提供几个示例,更多内容可参见该文档。
另外,kableExtra 包支持使用管道操作符 %>%,可以将 kable() 的输出结果连到 kableExtra 的样式函数上,例如表 6.7:
library(knitr)
library(kableExtra)
kable(grade, caption = "条纹表") %>%
kable_styling(latex_options = "striped")| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
6.1.2.1 设定字体尺寸
有的时候,在展示一些表格时,需要设定字体的尺寸,如放大或缩小某些特定问题。kableExtra 包中的 kable_styling() 函数可以帮助用户对整个表进行样式化。例如,可以指定页面上表格的对齐方式、表格的宽度和字体大小。表 6.8 展示了一个使用小字体的例子:
kable(grade, booktabs = TRUE,
caption = "字体较小的表格") %>%
kable_styling(font_size = 8)| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
6.1.2.2 特定的行或列的样式
有时还需要对表格的行或列的具体样式进行调整,如加粗某行等。函数 row_spec() 和 column_spec() 可分别用于样式化单独的行和列。表 6.9 将第一行文字加粗并设为斜体,将第二行添加黑色背景,同时更改字体颜色为白色并旋转,给第三行文字加下划线并更改其字体,并给第四列加删除线:
kable(grade, align = 'c', booktabs = TRUE,
caption = "更改特定行或列的样式") %>%
row_spec(1, bold = TRUE, italic = TRUE) %>%
row_spec(2, color = 'white',
background = 'black', angle = 45) %>%
row_spec(3, underline = TRUE, monospace = TRUE) %>%
column_spec(4, strikeout = TRUE)| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张三 | 89 | 93 | 92 |
| 李四 | 90 | 97 | 85 |
| 王五 | 85 | 91 | 97 |
类似地,也可以使用 cell_spec() 函数来给单个单元格设定样式。
6.1.2.3 给行或列分组
回想 Excel 里的操作,对单元格进行合并的操作可以给行或列进行分组。在 R Markdown 中,行和列可以分别通过函数 pack_rows() 和 add_header_above() 来进行分组。另外,也可以通过 collapse_rows() 来折叠行,这样一个单元格可以跨越多个行。表 6.10 展示了一个给标题列分组后的表格:
grade3 <- data.frame(姓名 = c("张三","李四","王五"),
物理 = c(90,90,85),
化学 = c(86,92,80),
生物 = c(94,85,90),
政治 = c(93,97,95),
历史 = c(92,84,80),
地理 = c(99,89,95),
计算机 = c(92,95,97),
体育 = c(85,99,95))
kable(grade3, booktabs = TRUE,
caption = "对标题列进行分组") %>%
add_header_above(c(" " = 1, "理科" = 3,
"文科" = 3, "其它" = 2))| 姓名 | 物理 | 化学 | 生物 | 政治 | 历史 | 地理 | 计算机 | 体育 |
|---|---|---|---|---|---|---|---|---|
| 张三 | 90 | 86 | 94 | 93 | 92 | 99 | 92 | 85 |
| 李四 | 90 | 92 | 85 | 97 | 84 | 89 | 95 | 99 |
| 王五 | 85 | 80 | 90 | 95 | 80 | 95 | 97 | 95 |
对于 add_header_above() 中的命名向量,其名称是显示在表头中的文本,向量的整数值表示一个名称应该跨越多少列,例如,"理科" = 3 表示 理科 应该跨越三列。
表 6.11 提供了 pack_rows() 的示例,其中 index 参数的含义类似于之前解释过的 add_header_above() 参数:
kable(grade3, booktabs = TRUE,
caption = "对行进行折叠") %>%
pack_rows(
index = c("一班" = 1, "二班" = 2)
)| 姓名 | 物理 | 化学 | 生物 | 政治 | 历史 | 地理 | 计算机 | 体育 |
|---|---|---|---|---|---|---|---|---|
| 一班 | ||||||||
| 张三 | 90 | 86 | 94 | 93 | 92 | 99 | 92 | 85 |
| 二班 | ||||||||
| 李四 | 90 | 92 | 85 | 97 | 84 | 89 | 95 | 99 |
| 王五 | 85 | 80 | 90 | 95 | 80 | 95 | 97 | 95 |
6.1.2.4 按比例缩小 LaTeX 中的表格
有一些特性是 HTML 或 LaTeX 输出格式特有的。例如,横向打印格式只在 LaTeX 中有意义,所以 kableExtra 中的 landscape() 函数只对 LaTeX 格式的输出有效。对于一个比较宽的表格(表 6.12),(表 6.13)展现了如何将表格按比例缩小以适应页面的宽度(否则该表格会太宽):
grade4 <- merge(grade, grade3, by = "姓名")
kable(grade4,
booktabs = TRUE,
caption = "原始表格(太宽)")| 姓名 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | 政治 | 历史 | 地理 | 计算机 | 体育 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 张三 | 89 | 93 | 92 | 90 | 86 | 94 | 93 | 92 | 99 | 92 | 85 |
| 李四 | 90 | 97 | 85 | 90 | 92 | 85 | 97 | 84 | 89 | 95 | 99 |
| 王五 | 85 | 91 | 97 | 85 | 80 | 90 | 95 | 80 | 95 | 97 | 95 |
kable(grade4,
booktabs = TRUE,
caption = "缩小后的表格") %>%
kable_styling(latex_options = "scale_down")| 姓名 | 语文 | 数学 | 英语 | 物理 | 化学 | 生物 | 政治 | 历史 | 地理 | 计算机 | 体育 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 张三 | 89 | 93 | 92 | 90 | 86 | 94 | 93 | 92 | 99 | 92 | 85 |
| 李四 | 90 | 97 | 85 | 90 | 92 | 85 | 97 | 84 | 89 | 95 | 99 |
| 王五 | 85 | 91 | 97 | 85 | 80 | 90 | 95 | 80 | 95 | 97 | 95 |
6.1.3 其它表格包
还有很多其他的 R 包可以用来生成表格。本节引入 kable() (见第 6.1.1 节)和 kableExtra (见第 6.1.2 节)的主要原因不是它们比其他包更好,而是因为作者们只熟悉它们,而且它们的功能可以涵盖大部分的日常使用需求。接下来本节将列出一些已知的其它软件包,感兴趣的读者可以去尝试并决定哪一个最适合自己。
flextable (R-flextable?) 和 huxtable (Hugh-Jones 2021):flextable 和 huxtable 支持多种表格输出格式的包。它们都支持 HTML、LaTeX 以及 Office 格式,并且包含最常见的表格特性(例如条件格式化)。更多关于 flextable 的信息可参见:https://davidgohel.github.io/flextable/,huxtable 的说明文档则在:https://hughjonesd.github.io/huxtable/。
gt (R-gt?):这个 R 包允许用户将表格的不同部分组合在一起,例如表头(标题和副标题)、列标签、表格主体、行组标签以及表格的脚注,从而组成一个完整的表格,其中有些部分是可选择性添加的。还可以格式化数字,并为单元格添加背景阴影。目前 gt 主要支持 HTML 输出。28更多关于 gt 的信息可参见:https://gt.rstudio.com。
formattable (R-formattable?):这个 R 包提供了一些格式化数字的工具函数(如
percent()和accounting()),以及对列进行样式化的函数(如格式化文本,用背景阴影或颜色条注释数字,或在单元格中添加图标等等)。和 gt 相同,formattable 包也主要支持HTML格式。更多信息可参见GitHub项目:https://github.com/renkun-ken/formattable/。DT (R-DT?):它只支持 HTML 格式。DT 构建在 JavaScript 库 DataTables 之上,它可以将静态表转换为HTML页面上的交互式表。使用者可以对表进行排序、搜索和分页。DT 还支持格式化单元格,与 Shiny 一起构建交互式应用程序,并包含了大量的 DataTables 扩展(例如,可以将表格导出到Excel,或交互式重新排列表格的列)。更多信息可参见:https://github.com/rstudio/DT/。
reactable (R-reactable?):与 DT 类似,这个包也基于 JavaScript 库创建交互式表。它在某些方面比 DT 更好(比如行分组和聚合操作,以及嵌入HTML小部件),但 reactable 并不包含 DT 全部的特性。更多信息可参见:https://glin.github.io/reactable/。
rhandsontable(R-rhandsontable?):这个包也类似于 DT,并且和 Excel 比较像(例如,可以直接在表中编辑数据)。更多信息可参见:https://jrowen.github.io/rhandsontable/。
pixiedust (R-pixiedust?):这个包通过 broom 包(R-broom?)来为为模型结果(如线性模型)创建表格,它支持 Markdown、HTML 以及 LaTeX 输出格式。更多信息可参见:https://github.com/nutterb/pixiedust/。
stargazer (R-stargazer?):格式化回归模型和汇总统计表。更多信息可参见:https://cran.r-project.org/package=stargazer/。
xtable (Dahl et al. 2019);这个包可能是最早的创建表格的包,其第一次发布是在 2000 年。它同时支持LaTeX和HTML格式。该软件包可在 CRAN 上访问:https://cran.r-project.org/package=xtable/。
还有一些其它生成表格的包,这里不再进一步介绍,只是在这里列出它们,以供感兴趣者参考:tables (R-tables?)、pander (Daróczi and Tsegelskyi 2022)、tangram (R-tangram?)、ztable (R-ztable?) 以及 condformat (R-condformat?)。
6.2 块选项
本节和接下来的第 6.4、6.6 两节进一步展示一些与 knitr 代码块选项相关的编程技巧。
R Markdown 支持超过 50 个块选项 用于调整 knitr 处理代码块的方式,完整列表可参阅在线文档https://yihui.org/knitr/options/。
下面的几节展示了在单个代码块中使用块选项的例子,希望为全部代码块统一设置块选项的读者可以参考第 2.7 节。
6.2.1 在块选项中使用变量
通常情况下,块选项中会使用常数(如:fig.width = 6),但有些时候仅使用常数无法满足需求,例如应展现的图像大小可能来源于其它代码块的结果,而非一成不变,每次根据结果来手动调整就会费时又费力。
块选项支持任意或简单或复杂的 R 表达式。一种特殊的情况是将代码块中定义的表达式传递给一个块选项。例如,为了满足图像大小变化的需求,可以在文档的一个代码块中定义关于图像宽度的变量,然后在其他代码块中使用它:
```{r}
my_width <- 7
```
```{r, fig.width=my_width}
plot(cars)
```另外,块选项中也可以使用更为复杂的函数,例如可以使用 if-else 语句来调整图片大小:
```{r}
fig_small <- FALSE # 输出更大的图片需要改为 TRUE
width_small <- 4
width_large <- 8
```
```{r, fig.width=if (fig_small) width_small else width_large}
plot(cars)
```不仅如此,还可以只在所需要的包可使用时才运行一个代码块(eval=FALSE 意味着不运行该代码):
```{r, eval=require('leaflet')}
library(leaflet)
leaflet() %>% addTiles()
```需要注意的是,require('package') 只有当这个包已安装且可使用时才会返回 TRUE,否则会返回 FALSE。
6.2.2 允许错误
默认情况下,如果文档中的某一个代码块运行错误,R Markdown 将终止当前编译并跳过剩余代码块。但瑕疵掩不住美玉,一次报错不妨碍整体的质量;失败是成功之母,一次报错更是珍贵的学习机会。出于种种原因,用户希望在代码块报错的时候显示错误并继续运行,可以使用块选项 error = TRUE,例如:
```{r, error=TRUE}
1 + "a"
```这样在编译 R Markdown 文档后,将在输出文档中看到如下的错误消息:
Error in 1 + "a": non-numeric argument to binary operator6.2.3 控制输出
默认情况下,knitr 会显示代码块的所有可能输出,包括源代码、提示信息(message)、警告(warning)、文本输出和图像输出等,但有时处于种种目的,只需要部分输出。本节将详细介绍如何控制各类结果的输出。
6.2.3.1 隐藏源代码、提示信息、警告、文本输出或图像输出
用户可以隐藏源代码和各类输出结果,包括信息、警告、文本和图像,可以使用相应的块选项来单独隐藏它们:
隐藏源代码:
```{r, echo=FALSE}
1 + 1
```
隐藏提示信息(message):
```{r, message=FALSE}
message("这个message不会显示")
```
隐藏警告(warning):
```{r, warning=FALSE}
# 这将生成一个warning,但不会被输出
1:2 + 1:3
```
隐藏文本输出(也可以使用`results = FALSE`):
```{r, results='hide'}
print("这个文本输出不会显示。")
```
隐藏图形输出:
```{r, fig.show='hide'}
plot(cars)
```
需要注意的是,上面的代码块会生成图形,它只是没有显示在输出中而已。一个常见的需要隐藏的输出元素是某些包的加载信息。例如,在运行 library(tidyverse) 或 library(ggplot2) 时,可能会看到一些正在加载的 message。这类 message 也可以通过块选项 message = FALSE 来隐藏。
另外,还可以通过索引来有选择地显示或隐藏这些元素。下面的示例只输出了源代码的第四个和第五个表达式(注意,一个注释会被算作一个表达式)、前两个 message 以及第二个和第三个 warning:
```{r, echo=c(4, 5), message=c(1, 2), warning=2:3}
# 一种生成服从N(0,1)分布的随机数的方法
x <- qnorm(runif(10))
# 在实践中还可以使用
x <- rnorm(10)
x
for (i in 1:5) message('这是 message ', i)
for (i in 1:5) warning('这是 warning ', i)
```这些选项也支持负索引,例如,echo = -2 表示在输出中排除源代码的第二个表达式。
类似地,可以通过使用 fig.keep 选项 来选择显示或隐藏哪些图。例如,fig.keep = 1:2 意味着保留前两幅图。这个选项有一些快捷的方式,如 fig.keep = "first" 将只保留第一幅图、fig.keep = "last" 只保留最后的图以及 fig.keep = "none" 将丢弃所有的图。需要注意的是,fig.keep = "none" 和 fig.show = "hide" 这两个选项是不同的,后者将生成图像文件,只是会隐藏它们,而前者则根本不会生成图像文件。
对于 html_document 输出中的源代码块,如果不想完全省略它们(echo = FALSE),可以参考3.1.2.6节,来学习如何在页面上折叠它们,并允许报告用户通过单击展开按钮来展开它们。
6.2.3.2 隐藏代码块的所有输出
有的时候,可能希望正常执行代码块但隐藏源代码和所有输出。与使用第 6.2.3.1 节中提到的单独选项不同,include = FALSE 可以同时隐藏源代码和输出:
```{r, include=FALSE}
# 任意 R 代码
```注意,设置了 include=FALSE 的代码块仍会被运行,但读者将看不到任何的源代码、提示信息、警告、文本输出或图像输出等。
6.2.3.3 将文本输出压缩到源代码块中
R Markdown 默认把源代码和输出放置在不同的容器中。如果想把输出和源代码放在一起,可以使用块选项 collapse = TRUE,例如:
1 + 1
## [1] 2
1:10
## [1] 1 2 3 4 5 6 7 8 9 106.2.3.4 原样输出文本为 Markdown (*)
默认情况下,代码块的文本输出与源代码的样式一致。如果希望把代码块的输出直接作为后续的 Markdown 文本,可以通过添加块选项 results = 'asis' 来解决。这个选项告诉 knitr 不要将文本输出逐字包装成代码块,而是“原样”对待它。当想要从 R 代码动态生成内容时,这一点特别有用。例如,可以使用选项 results = 'asis' 从以下代码块生成 iris 数据的列名列表:
cat(paste0('- `', names(iris), '`'), sep = '\n')Sepal.LengthSepal.WidthPetal.LengthPetal.WidthSpecies
连字符(-)是 Markdown 中用于生成无序列表的语法,其中反引号是可选的。若没有设置 results = 'asis' 选项,则上述代码块的输出为:
cat(paste0('- `', names(iris), '`'), sep = '\n')## - `Sepal.Length`
## - `Sepal.Width`
## - `Petal.Length`
## - `Petal.Width`
## - `Species`下面是一个完整的例子,展示了如何在 for 循环中为 mtcars 数据的所有列生成节标题、段落和图:
---
title: 以编程的方式生成内容
---
通过代码块选项 `results = 'asis'`,可以将文本输出为 Markdown。
同时也可以与图片混合。
```{r, mtcars-plots, results='asis'}
for (i in names(mtcars)) {
cat("\n\n# 变量 `", i, "` 的概要\n\n")
x <- mtcars[, i]
if (length(unique(x)) <= 6) {
cat("`", i, "` 是一个分类变量。\n\n")
plot(table(x), xlab = i, ylab = "频率", lwd = 10)
} else {
cat("连续变量 `", i, "` 的直方图。\n\n")
hist(x, xlab = i, main = "")
}
}
```需要注意的是,上述示例代码中添加了过多的换行符(\n),从而将不同的元素在 Markdown 中清晰地分开。在不同的元素之间使用过多的换行符是无害的,但是如果换行符不够,就会产生问题。例如,下面的 Markdown 文本就会产生很多的歧义:
# 这是一个标题吗?
这是一个段落还是标题的一部分呢?

# 这行又是什么?如果产生了更多的空行(可以由cat('\n')生成),则可以避免歧义:
# 这是一个标题!
这绝对是个段落。

# 这是另一个标题cat() 函数不是唯一可以生成文本输出的函数,另一个常用的函数是 print()。但需要注意的是,print() 经常被 隐式 调用来打印对象,这就是为什么在 R 控制台(console)中输入一个对象或值后会看到输出。例如,当在 R 控制台中输入 1:5 并按下 Enter 键时,会看到输出,这是因为 R 实际上隐式地调用了 print(1:5)。经常令人感到困惑的是,不能在表达式(例如 for 循环)中直接生成输出,而如果在 R 控制台上输入对象或值,它们将被正确打印出来。这个主题非常技术性,具体细节可以参看博文“The Ghost Printer behind Top-level R Expressions”。如果对技术细节不感兴趣,只要记住这条规则即可:如果在 for 循环中没有看到输出,那么可能应该使用 print() 函数来显式地打印对象。
6.2.4 自动格式化源代码
多人协作中,维持统一的代码风格往往是令人头疼的问题,对空格、换行、括号等元素的不同使用习惯因人而异。即便是在单人工作中,时刻手动调整代码风格仍是件苦功夫。为了解决这个问题,R Markdown 提供了一个块选项 tidy 可以自动美化代码块的格式。
当设置块选项 tidy = TRUE 时, R 的源代码将被 formatR 包 (Xie 2022b)的 tidy_source() 函数重新格式化。tidy_source() 可以在几个方面重新格式化代码,比如在大多数操作符周围添加空格、适当缩进代码以及用 <- 替换赋值操作符 = 。块选项 tidy.opts 可以是传递给 formatR::tidy_source() 的一个参数列表,例如:
```{r, tidy=TRUE, tidy.opts=list(arrow=TRUE, indent=2)}
# 混乱的 R 代码...
1+ 1
x=1:10#有些使用者更喜欢用 '<-' 来作为赋值操作符
if(TRUE){
print('Hello world!') # 缩进 2 个空格
}
```输出结果为:
# 混乱的 R 代码...
1 + 1
x <- 1:10 #有些使用者更喜欢用 '<-' 来作为赋值操作符
if (TRUE) {
print("Hello world!") # 缩进 2 个空格
}块选项 out.width 可以控制输出的宽度。如果想进一步控制源代码的宽度,则可以在设置 tidy = TRUE 时使用 width.cutoff 参数,例如:
```{r, tidy=TRUE, tidy.opts=list(width.cutoff=50)}
# 一个很长的表达式
1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+
1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1+1
```输出结果为:
# 一个很长的表达式
1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 +
1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 +
1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 +
1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1更多可能的参数可以参见帮助页 ?formatR::tidy_source,也可以浏览 https://yihui.org/formatR/ 来了解这个函数的示例和局限性。
另外,还可以通过设定块选项 tidy = 'styler' 来使用 styler 包(R-styler?)重新格式化 R 代码,其中的格式化函数为 styler::style_text()。styler 包比 formatR 具有更丰富的特性。例如,它可以对齐函数参数并使用管道操作符 %>%。块选项 tidy.opts 同样可以用于将附加参数传递给 styler::style_text(),例如:
```{r, tidy='styler', tidy.opts=list(strict=FALSE)}
# 对齐赋值操作符
a <- 1 # 一个变量
abc <- 2 # 另一个变量
```R Markdown 默认设置 tidy = FALSE, 不会自动格式化代码。
6.2.5 调整文本输出中的前导符号
默认情况下,R Markdown 会在文本输出的前面插入两个符号 ##,那么这个符号能不能更改或者干脆删除呢?第 6.2.3.4 节介绍了通过在添加 results = 'asis' 选项来生成 Markdown 形式输出的方法。但如果只是想调整前导符号,而仍然想将文本放在单独的块中,则可以通过块选项 comment 来实现。如果要删除 ##,可以使用空字符串,例如:
```{r, comment=""}
1:100
```当然,可以使用任何其他的字符值,例如,comment = "#>"。为什么 comment 选项默认为 ## 呢?这是因为 # 表示 R 中的注释,无论代码块的输出是什么,读者都可以直接复制整段代码并在 R 中运行。
6.2.6 为代码块添加属性 (*)
第 3.1.2.5 节展示了一些基于块选项 class.source 样式化代码块的示例。knitr 提供了更多类似的选项,如 class.output、class.message、class.warning 以及 class.error。另外的一个常见类是 .numberLines,可以用于为代码块添加行号。演示如下:
```{r, class.source='numberLines', eval=FALSE}
if (TRUE) {
x <- 1:10
x + 1
}
```注意,为了让 html_document 格式显示行号,需要在 YAML 元数据中使用任意非默认的高亮选项,例如 hightlight: pygment。
作为一个技术性拓展,块选项 class.* 只是 attr.* 的特殊情况,例如,class.source = 'numberLines' 等价于 attr.source = '.numberLines'(注意前面的点 .),但 attr.source 可以取任意的属性值,例如 attr.source = c('.numberLines', 'startFrom="11"')。同理,可以用类似的 方法设置 attr.output、attr.message、attr.warning 以及 attr.error 等属性。
第 3.1.2.5 节介绍了 R Markdown 内置的 "bg-primary","bg-success","bg-info","bg-warning" 和 "bg-danger" 等样式类。本节的知识可以让读者定义自己的样式类,例如,可以在 CSS 中定义一个 myClass 类及其外观,然后通过 class.source = 'myclass' 来为代码块添加定义好的样式。例如:
定义 myClass 类:
```{css, echo = FALSE}
@import url('https://fonts.googleapis.com/css2?family=Fira+Code:wght@500&display=swap');
.myClass {
background-color: #f1f3f5;
padding: 0.4rem;
border-radius: 0.25rem;
border-left: 3px solid #31bae9;
border-bottom: none;
box-shadow: 0px 8px 5px -8px rgba(0,0,0,0.75);
}
.myClass code {
font-family: 'Fira Code', monospace;
}
```
应用 myClass 类:
```{r, class.source = "myClass", eval = FALSE}
state.x77 |>
as.data.frame() |>
tibble::rownames_to_column("State") |>
dplyr::group_by(State) |>
dplyr::summarise(avg_murder_rate = mean(Murder))
```属性 attr 也支持自定义行内 CSS 样式,例如
```{r, attr.output='style="background: pink;"'}
if (TRUE) {
x <- 1:10
x + 1
}
```1 + 1## [1] 2基于类和属性的选项对 HTML 输出格式是通用的,部分情况下也支持其他格式。这些属性需要被 Pandoc 或第三方的包支持。例如 Pandoc 中,.numberLines 属性适用于 HTML 和 LaTeX 输出;第三方的包则通常需要通过一个 Lua 过滤器,感兴趣者请参见:https://bookdown.org/yihui/rmarkdown-cookbook/lua-filters.html。
更多类与属性的例子参见第 6.4.3 节。
6.2.7 同一张图的多种图像输出格式
在大多数情况下,报告可能只需要一种图像格式,例如 png 或 tiff。但有些时候,一些报告需要提交多种格式的图像,这就需要进一步了解图像格式选择的原理。
图像格式由块选项 dev 控制,即渲染图像的图像设备,这个选项的取值可以为设备名(即输出格式)的向量,例如:
```{r, dev=c('png', 'pdf', 'svg', 'tiff')}
plot(cars)
```输出文档中只会呈现第一种格式的图像,但其它格式的图像也会被生成。这里需要注意的是,在默认情况下,图像文件在输出文档呈现后会立即被删除,如要保存这些文件,请参见7.1.5节。
6.2.8 图像的后期加工 (*)
fig.process 可用于对代码块生成的图片做后期加工。fig.process 接受一个函数,其中的第一个参数是当前图片的路径,最终应该返回加工后的图片的路径。该函数还可以有第二个可选参数 options,代表一个由当前块选项组成的列表,这个列表可以用于定制图片处理的细节。
下面的例子展示了如何使用一个功能强大的 magick包 (Ooms 2021) 来在图像中添加 R logo。首先,定义一个函数 add_logo():
install.packages("magick")add_logo = function(path, options) {
# 代码块中创建的图像
img = magick::image_read(path)
# R logo
logo = file.path(R.home("doc"), "html", "logo.jpg")
logo = magick::image_read(logo)
# 默认的重力方向为西北,用户可以通过代码块来改变它
# option magick.gravity
if (is.null(g <- options$magick.gravity)) g = 'northwest'
# 在图像中添加 logo
img = magick::image_composite(img, logo, gravity = g)
# 写入新的图像中
magick::image_write(img, path)
path
}该函数会读取图像的路径,添加 R logo,并将新图像保存到原路径。在默认情况下,logo 会被添加到图像的左上角(西北方向),但用户可以通过自定义块选项 magick.gravity(这个选项名可以是任意的)来自定义位置。
下一步就是将处理函数 add_logo() 应用到代码块中,并使用块选项 fig.process = add_logo 和 magick.gravity = "northeast",所以 logo 会被添加到右上角。实际输出见图 6.3。
par(mar = c(4, 4, .1, .1))
hist(faithful$eruptions, breaks = 30, main = '', col = 'gray', border = 'white')图 6.3: 通过块选项 fig.process 来给一幅图添加 R logo。
下面的例子展示了 fig.process 选项的另一个应用,其中 pdf2png() 函数可以将 PDF 图像转换成 PNG 格式。第 6.2.9 节介绍了如何使用 tikz 图像设备来生成图,但该设备生成的 PDF 图不适用于非 LaTeX 的输出文档。而在设置块选项 dev = "tikz" 和 fig.process = pdf2png 后,就可以显示图 6.4 的 PNG 版本了。
pdf2png = function(path) {
# 只对非LaTeX的输出进行转换
if (knitr::is_latex_output()) return(path)
path2 = xfun::with_ext(path, "png")
img = magick::image_read_pdf(path)
magick::image_write(img, path2, format = "png")
path2
}6.2.9 输出高质量的图像 (*)
不同格式的图像往往在输出质量上有差异。rmarkdown 包为不同的输出格式设置了合理的默认图像设备。例如,对 HTML 输出格式使用 png() 设备,所以 knitr 将生成 png 绘图文件;而对 PDF 输出格式则使用 pdf() 设备。如果对默认图像设备的输出质量不满意,可以通过块选项 dev 来更改它们。knitr 支持的设备为:"bmp","postscript","pdf","png","svg","jpeg","pictex","tiff","win.metafile","cairo_pdf","cairo_ps","quartz_pdf","quartz_png","quartz_jpeg","quartz_tiff","quartz_gif","quartz_psd","quartz_bmp","CairoJPEG","CairoPNG","CairoPS","CairoPDF","CairoSVG","CairoTIFF","Cairo_pdf","Cairo_png","Cairo_ps","Cairo_svg","svglite","ragg_png",以及"tikz"。
通常情况下,图像设备名也是函数名。更多关于图像设备的信息可以参阅 R 的帮助页面。例如,可以在 R 的控制台中输入 ?svg 来了解关于 svg 设备的细节,它包含在 R 的基础包中,所以不需要额外安装。需要注意的是,quartz_XXX 设备是基于 quartz() 函数的,并且它们仅在 macOS 上可用;CairoXXX 设备来自的 R 包 cairoDevice29;svglite 设备来自 svglite 包 (Hadley Wickham et al. 2022);tikz 设备则在 tikzDevice 包 (Sharpsteen and Bracken 2020)中。如果需要使用这些包中的图像设备,必须先安装这些包。
通常,矢量图比位图质量更高,并且可以在不损失质量的情况下缩放矢量图。对于 HTML 输出,可以使用 dev = "svg" 或 dev = "svglite" 来绘制 SVG(可缩放矢量图,Scalable Vector Graphics)。需要注意的是,默认情况下 png 设备生成的图像为位图。
对于 PDF 输出,如果对图像中的字体非常挑剔,可以使用 dev = "tikz",因为它提供了对 LaTeX 的原生支持,这意味着图像中的所有元素,包括文本和符号,都可以通过 LaTeX 以高质量呈现。图 6.4 展示了一个在R图像中用块选项 dev = "tikz" 添加 LaTeX 数学表达式的例子。
par(mar = c(4, 4, 2, .1))
curve(dnorm, -3, 3, xlab = '$x$', ylab = '$\\phi(x)$',
main = 'The density function of $N(0, 1)$')
text(-1, .2, cex = 3, col = 'blue',
'$\\phi(x)=\\frac{1}{\\sqrt{2\\pi}}e^{\\frac{-x^2}{2}}$')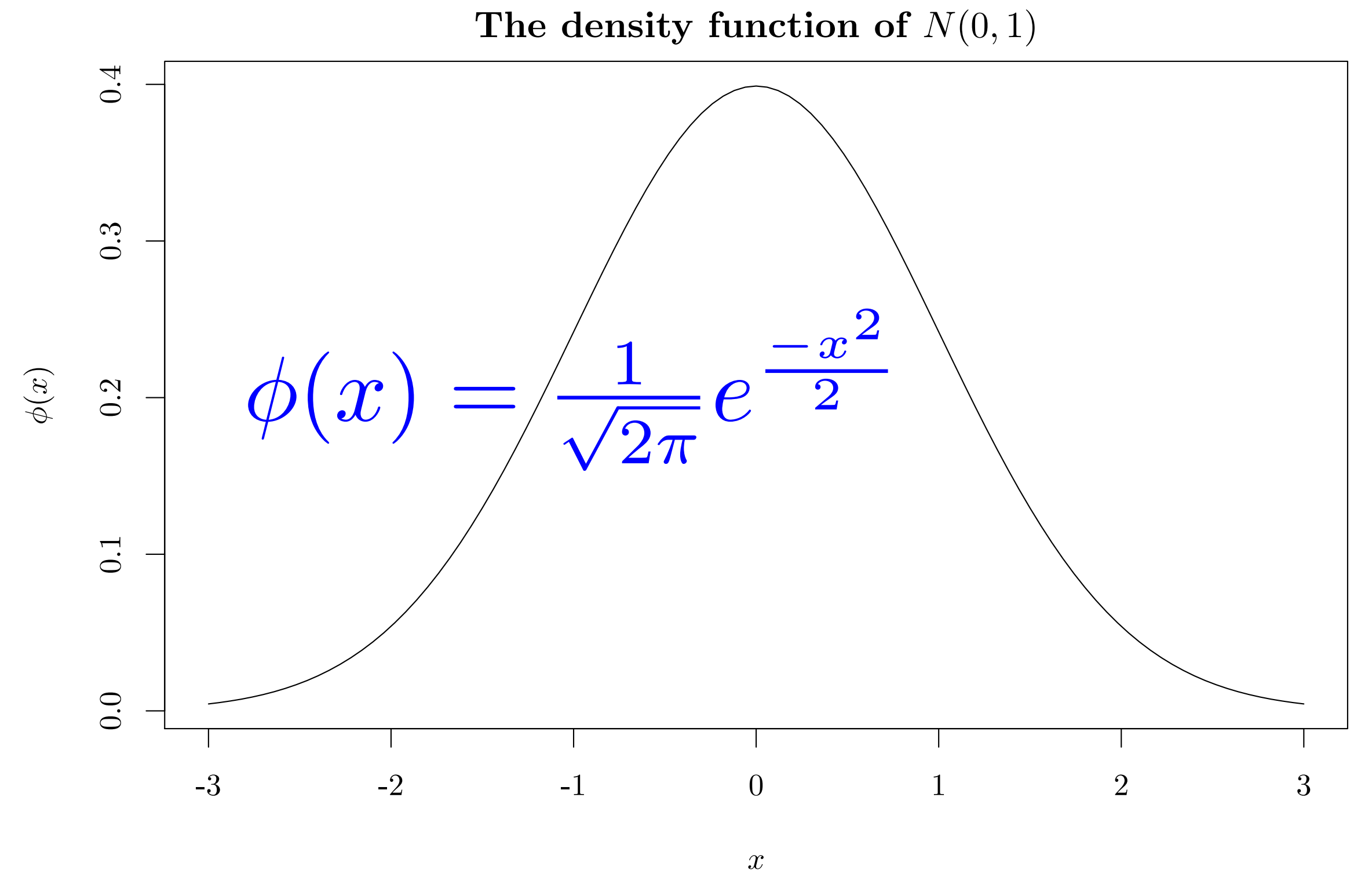
图 6.4: 通过 tikz 设备呈现的图像。
需要注意的是,R 的基础包实际上支持数学表达式,但它们不是通过 LaTeX 呈现的(具体细节可参见 ?plotmath)。此外,还有几个高级选项可以调整 tikz 设备的排版细节(参见 ?tikzDevice::tikz)。例如,如果图像中包含多字节字符,可以设置选项:
options(tikzDefaultEngine = 'xetex')这是因为在处理 LaTeX 文档中的多字节字符时,xetex 通常比默认引擎 pdftex 要好。
tikz 设备主要有两个缺点。首先,它需要安装 LaTeX,但这其实并不会很麻烦(见第 2.2.1 节),虽然还需要几个 LaTeX 包,但这些包也可以通过 TinyTeX 很方便地安装:
tinytex::tlmgr_install(c('pgf', 'preview', 'xcolor'))其次,tikz 设备渲染图的速度通常要慢得多,因为这个设备会生成 LaTeX 文件,并且必须将其编译成 PDF。如果觉得代码块很耗时,可以通过块选项 cache = TRUE 来启用缓存(见第 6.5 节)。
图 6.4 实际上也使用了块选项 fig.process = pdf2png,当输出格式不是 LaTeX时,pdf2png 函数可以将 PDF 图转换为 PNG,其定义见第 6.2.8 节。如果没有这一转换,可能无法在 Web 浏览器中查看该书在线版本中的 PDF 图。
6.2.10 带有低级绘图功能的逐步绘图 (*)
在 R 中,有两种类型的绘图函数可以用来画图:高级的绘图函数用于创建新图,以及低级的绘图函数用于在现有的图中添加元素,更多信息请参见 R 手册《An Introduction to R》的第 12 章(“Graphical procedures”)。
在默认的情况下,当使用一系列低级的绘图函数来修改以前的图像时,knitr 不会显示中间的图,只会显示所有函数执行后的最后一个图。
然而有的时候,尤其是在教学过程中,展示中间的图像是很有用的。为此,可以设置块选项 fig.keep = 'low' 来保留各低级函数更改后的图。例如,图 6.5 和图 6.6 来自一个带有块选项 fig.keep = 'low' 的单个代码块,尽管它们很像两个代码块的输出结果。不仅如此,本节还通过块选项 fig.cap=c('cars ...', '在现有的...') 给它们分配了不同的标题。
par(mar = c(4, 4, .1, .1))
plot(cars)
图 6.5: cars 数据的点图
fit = lm(dist ~ speed, data = cars)
abline(fit)
图 6.6: 在现有的点图中添加一条回归线
如果想在不同的代码块中继续修改这张图,请参阅第 6.6.5 节。
6.2.11 在代码块中自定义对象的打印格式 (*)
在默认的情况下,代码块中的对象会通过 knitr::knit_print() 函数来打印,基本上就相当于 R 中的 print(),但这往往并不能满足用户的需求。有的时候用户可能希望直接输出表格,除了第 6.1 节提到的方法外,还有更便捷的方法实现。
本质上,knit_print() 函数是一个 S3 泛型函数,这意味着可以通过在其上注册 S3 方法来拓展输出方式。下面的例子展示了如何通过 knitr::kable() 来自动将数据框打印成表格:
---
title: 使用自定义的 `knit_print` 方法来打印数据框
---
首先,定义一个 `knit_print` 方法,并注册它:
```{r}
knit_print.data.frame = function(x, ...) {
res = paste(c("", "", knitr::kable(x)), collapse = "\n")
knitr::asis_output(res)
}
registerS3method(
"knit_print", "data.frame", knit_print.data.frame,
envir = asNamespace("knitr")
)
```
现在可以在数据框上测试这个自定义的打印方法。
需要注意的是,之后不再需要显式地调用 `knitr::kable()` 了。
```{r}
head(iris)
```
```{r}
head(mtcars)
```更多关于 knit_print() 函数的信息可参见 knitr 包的简介:
vignette('knit_print', package = 'knitr')printr 包 (R-printr?)提供了一些 S3 方法来自动将 R 对象打印为表格。只需要在 R 代码块中输入 library(printr),所有的方法都将自动注册。
一些 R Markdown 输出格式,如 html_document 和 pdf_document 提供了一个选项 df_print,它允许用户自定义数据框的打印行为。例如,如果想通过 knitr::kable() 来将数据框打印为表格,可以设置选项:
---
output:
html_document:
df_print: kable
---有关输出格式的更多细节可参阅输出格式的帮助页(如 ?rmarkdown::html_document),可以了解 df_print 选项支持哪些输出格式,以及对应的值是什么。
读者还可以通过块选项 render 来完全代替打印函数 knit_print(),render 可以使用任何函数来打印对象。例如,如果想使用 pander 包来打印对象,可以设置块选项 render 为函数 pander::pander:
```{r, render=pander::pander}
head(iris)
```最终得到的结果为:
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
render 选项让用户可以充分定制任意对象的打印效果。
6.2.12 选项钩子 (*)
选项钩子(option hook)可以在代码块执行前操作块选项的值,或者定义新的块选项。例如,用户可能希望自动调整所有代码块的图片宽度 fig.width 不小于高度 fig.height。knitr 提供了对象 opts_hooks 来设置一个选项钩子,其中的 set() 用于覆盖块选项的执行逻辑。例如,可以在 knitr::opts_hooks$set() 中指定 fig.width,使它总是大于等于 fig.height:
knitr::opts_hooks$set(fig.width = function(options) {
if (options$fig.width < options$fig.height) {
options$fig.width = options$fig.height
}
options
})opts_chunk$set() 中的每一个元素都是一个函数,它的第一个参数是一个包含当前代码块所有选项的列表 options,由 knitr 在执行代码块前自动传入。如果想要修改选项,就可以修改 options 并返回更新后的列表。
对于下面的代码块,如果设置了上述的选项钩子,则 fig.width 将被修改为 6 而不是最初定义的 5:
```{r fig.width = 5, fig.height = 6}
plot(1:10)
```选项钩子只会在块选项不是 NULL 时执行,而 fig.width 有非 NULL 的默认值,所以能确保该钩子执行。
另外,第 6.2.5 节的最后一个例子介绍了如何将输出格式调整成类似于 R 控制台(console)的格式,这一功能也可以用选项钩子实现,从而可以使用一个单独的块选项 console = TRUE 来代替 comment = "" 和 prompt = TRUE。需要注意的是,console 不是一个内置的 knitr 块选项,而是一个自定义的任意的选项名,它的默认值是 NULL。下面是一个完整的例子:
```{r, include=FALSE}
knitr::opts_hooks$set(
console = function(options) {
if (isTRUE(options$console)) {
options$comment <- ''; options$prompt <- TRUE
}
options
})
```
默认输出为:
```{r}
1 + 1
if (TRUE) {
2 + 2
}
```
设置 `console = TRUE` 时的输出为:
```{r, console=TRUE}
1 + 1
if (TRUE) {
2 + 2
}
```opts_hooks$set() 的参数可以是 knitr 内置的选项,也可以是自定义选项。下面的例子定义了新的块选项 numberLines,用于添加行号,涉及的元素包括源代码块、文本输出、提示信息、警告以及报错信息。
knitr::opts_hooks$set(
numberLines = function(options) {
attrs <- paste0("attr.", options$numberLines)
options[attrs] <- lapply(options[attrs], c, ".numberLines")
options
}
)
knitr::opts_chunk$set(
numberLines = c(
"source", "output", "message", "warning", "error"
)
)新选项 numberLines 在 options 列表中的 attr 元素上添加了一个新属性 .numberLines,实质上与 6.2.6 节中的 attr.<element> = ".numberLines" 设置是等价的。numberLines = c('source', 'output') 代表给源代码和文本输出添加行号,等同于 attr.source = '.numberLines' 和 attr.output = '.numberLines',而numberLines = NULL 会取消所有元素的行号。使用选项钩子的好处是更加简洁,且它不会覆盖现有的属性。用户也可以同时使用 numberLines 并设置属性:
```{r, numberLines="source", attr.source="startFrom='2'"}
# 编号从 2 开始
1 + 1
```6.3 结合其他语言
在 R Markdown 中,knitr 包除了支持 R 语言外,还支持许多其他语言。
不同语言代码块的表示方式类似,只需修改代码块中三个反引号后的花括号中的第一个单词即可。例如,```{r} 中的小 r 表示该代码块为 R 代码块,而 ```{python} 是指该代码块为 Python 代码块。其他语言也是使用类似的表达方式。
在 knitr 中,每种语言都通过语言引擎得到支持。语言引擎本质上是一些函数,它们以源代码和代码块选项作为输入,最后输出一个字符串。该过程通过 knitr::knit_engines 进行管理。读者可以使用以下方式检查现有引擎:
names(knitr::knit_engines$get())在作者的电脑下,包含了以下引擎:
## [1] "awk" "bash" "coffee" "gawk" "groovy" "haskell"
## [7] "lein" "mysql" "node" "octave" "perl" "psql"
## [13] "Rscript" "ruby" "sas" "scala" "sed" "sh"
## [19] "stata" "zsh" "asis" "asy" "block" "block2"
## [25] "bslib" "c" "cat" "cc" "comment" "css"
## [31] "ditaa" "dot" "embed" "exec" "fortran" "fortran95"
## [37] "go" "highlight" "js" "julia" "python" "R"
## [43] "Rcpp" "sass" "scss" "sql" "stan" "targets"
## [49] "tikz" "verbatim"注意:目前,大多数非 R 语言的代码块都是独立执行的。例如,同一文档中的所有
bash代码块都在各自的会话中单独执行,因此后面的bash代码块不能使用在先前bash代码块中创建的变量,更改后的工作目录在其他 bash 代码块中也不会一直存在。
本节重点介绍 Pyhton、Shell、SAS、Stata 以及 Asymptote 等语言引擎,如果读者其他语言引擎感兴趣,例如:SQL, Rcpp, Stan, JavaScript, Julia, C,和 Fortran 等,可参见书籍 《R Markdown: The definitive guide》(Xie, Allaire, and Grolemund 2018b) 中的第 2.7 节内容,也可以在以下网站中找到更多的例子: https://github.com/yihui/knitr-examples。
6.3.1 注册自定义语言引擎 (*)
除了使用内置的引擎外,读者可以使用 knitr::knit_engines$set() 注册一个自定义语言引擎。该引擎接受一个函数,例如:
knitr::knit_engines$set(foo = function(options) {
# 源代码在 options$code
})上面的代码注册了一个引擎,名称是 foo。接下来就可以使用以 ```{foo} 开头的代码块了。读者可以在 options$code 中以字符向量的形式访问代码块的源代码。例如,对于代码块:
```{foo}
1 + 1
2 + 2
```此时,所对应的 options$code 为字符向量 c('1 + 1', '2 + 2')。目前 foo 引擎对应的函数没有做任何工作,所以代码块的输出为空。
下面定义了一个自定义引擎 upper, 它将代码块的内容转换为大写:
knitr::knit_engines$set(upper = function(options) {
code <- paste(options$code, collapse = '\n')
if (options$eval) toupper(code) else code
})该 upper 引擎的作用是将 toupper 函数应用于代码,并以单个字符串的形式返回结果(通过 \n 连接所有代码行)。注意 toupper() 仅在代码块选项为 eval = TRUE 时才会应用,否则返回原始字符串。
以上例子展示了如何在引擎函数中使用 eval 之类的代码块选项。类似地,读者也可以考虑在函数体中添加 if (options$results == 'hide') return() 来隐藏代码块选项时的输出 results = 'hide' 。下面是一个使用 upper 引擎及其输出的简单示例:
```{upper}
Hello, **knitr** engines!
```HELLO, KNITR ENGINES!
下面的例子实现了一个基础的 Python 引擎,名为 py。30。首先获得代码块中完整的 Python 代码,随后使用 system2() 函数在命令行调用 Python 解释器,最后格式化输出。
knitr::knit_engines$set(py = function(options) {
code <- paste(options$code, collapse = '\n')
out <- system2(
'python3', c('-c', shQuote(code)), stdout = TRUE
)
knitr::engine_output(options, code, out)
})以上代码的主要思路和细节介绍如下:
将输入的 Python 代码作为字符串存储到
code中system2()调用 Python 解释器python -c 'code'执行代码,其中-c 'code'表示代码以字符串形式传入。并指定stdout = TRUE来收集(文本)输出。之后,将代码块选项、源代码和文本输出传递给函数
knitr::engine_output(),作为最终输出结果。knitr::engine_output()常用于返回运行结果,它会自动响应如echo = FALSE和results = 'hide'等块选项,所以这里不需要额外的if语句。
注意:knitr 中的许多语言引擎都是这样定义的(例如,使用
system2()来执行与语言对应的命令)。如果读者对技术细节感兴趣,可以在下面网站中查看大多数语言引擎的源代码 https://github.com/yihui/knitr/blob/master/R/engine.R。
现在,可以使用新的引擎 py 运行 Python 代码,例如:
```{py}
print(1 + 1)
```## 2如果觉得自己自定义的语言引擎版本比现有版本更好,读者甚至可以通过 knitr::knit_engines$set() 重写现有的语言引擎。但是,通常不建议这样做,因为这会让熟悉现有引擎的用户感到不解。不过本节主要目的是告诉读者,自定义语言引擎来替换现有引擎这种想法是可以实现的。
knitr 中许多语言的引擎使用了类似的实现方法。读者可以在 https://github.com/yihui/knitr/blob/master/R/engine.R 查看内置语言引擎的源代码。
6.3.2 运行 Python 代码并与 Python 交互
reticulate (Ushey, Allaire, and Tang 2022) 包提供了 R Markdown 中默认的 Python 引擎。要将 Python 代码块添加到 R Markdown 文档中,可以在代码块头部设置为```{python},例如:
```{python}
print("Hello Python!")
```Python 代码块支持部分 knitr 选项,比如 echo = FALSE 或 eval = FALSE 等。
reticulate 包的一个重要特性是它允许在 Python 和 R 运行环境中传递对象。例如,可以在 R 会话中通过 reticulate 包中的 py 对象访问或创建 Python 变量。例如:
---
output: html_document
---
```{r, setup}
library(reticulate)
```
在 Python 会话中创建一个变量 `x`:
```{python}
x = [1, 2, 3]
```
在 R 代码块中访问 Python 变量 `x`:
```{r}
py$x
```
在 R 中创建变量,并传递给 Python 会话,命名为 `y`:
```{r}
py$y <- head(cars)
```
在 Python 中使用变量 `y`:
```{python}
print(y)
print(type(y))
```输出如图 6.7 所示。
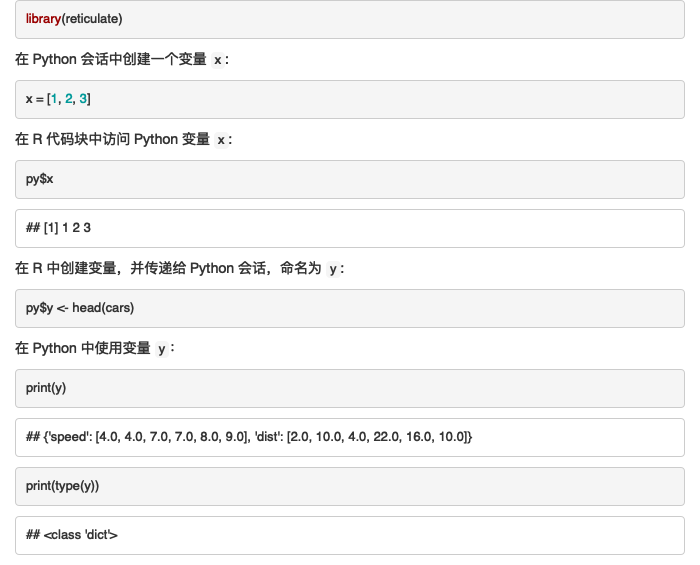
图 6.7: R 与 Python 代码块的交互
在 R 和 Python 代码块互相传递对象时,reticulate 包会自动地进行类型转换。例如 R 中的向量在 Python 中变为列表,R 中的列表在 Python 中变为字典,R 中的数据框 data.frame 类变为 Python 中 pandas 库支持的 DataFrame 类等。
更多 reticulate 包的知识可以查看文档 https://rstudio.github.io/reticulate 。
comment 和 prompt 可以让 Python 的输出格式模仿 R 控制台。在 R 控制台中,用户不会在文本输出前面看到##。如果想模仿 R 控制台的行为, 可以使用 comment = "" 和 prompt = TRUE,例如:
```{r, comment="", prompt=TRUE}
1 + 1
if (TRUE) {
2 + 2
}
```6.3.3 通过 asis 引擎有条件地执行内容
如果读者需要按一定条件输出某个代码块的内容,可以使用
asis 引擎来实现该功能。只需将条件加入到代码块选项 echo 中,当 echo = FALSE 时,对应代码块将不会显示内容,而当 echo = TRUE 时,对应代码块将会显示内容。下面给出一个简单的例子:
```{r}
getRandomNumber <- function() {
sample(1:6, 1)
}
```
```{asis, echo = getRandomNumber() == 4}
根据 https://xkcd.com/221/, 这里生成的是一个**真**随机数!
```其中,第一个代码块中设定了一个函数并赋值到 getRandomNumber 中。第二个代码块使用了 asis 引擎,并将 echo 参数进行了设置。只有当条件 getRandomNumber() == 4 (随机)为真时,该代码块中的文本才会显示。
6.3.4 执行 Shell 脚本
读者有时需要执行 Shell 脚本来批量运行一些代码,在 R Markdown 中,读者可以根据自己的喜好,使用 bash、 sh 或 zsh 之间的任何一种引擎来运行 Shell 脚本。下面是一个使用 bash 引擎的示例:
ls *.Rmd | head -n 5## [1] "01-intro.Rmd" "02-base.Rmd" "03-document.Rmd"
## [4] "04-working.Rmd" "05-interaction.Rmd"需要注意的是,bash 是通过用 R 函数 system2() 调用的,该函数将忽略配置文件,例如 ~/.bash_profile 和 ~/.bash_login等,这些文件中可能定义了一些命令的别名或修改过的环境变量(如 PATH 变量)等。如果想要复现终端(terminal)的运行结果,可以设置引擎参数 engine.opts = ‘-l’ 显式加载配置文件。例如:
```{bash, engine.opts='-l'}
echo $PATH
```如果想对所有 bash 块全局启用 -l 参数,可以在文档开头的全局代码块(global chunk)中设置:
knitr::opts_chunk$set(engine.opts = list(bash = '-l'))另外,还可以将其他参数作为字符向量提供给块选项 engine.opts,从而将其传递给 bash。
6.3.5 通过 cat 引擎将代码块内容写入文件
有时读者可能需要将代码块的内容写入文件。并在后续的代码块中引用该文件。一个简单的实现办法是使用 writeLines() 函数。例如:
writeLines("添加反斜杠是件头疼的事,到底是 '\t'、'\\t' 还是 '\\\\t'?", con = "my-file.txt")随后,需要使用 my-file.txt 文件中的内容时,可以用 readLines() 重新读取该文件。
当内容相对较长或包含特殊字符时,writeLines() 中繁琐的转义字符让代码的可读性较差。
注意:自 R 4.0.0 以来,这个问题已经大大缓解了,因为 R 开始支持
r"( )"中的原始字符串(参见帮助页面?Quotes),而且读者不需要记住所有关于特殊字符的规则。即使使用原始字符串,在代码块中显式地将长字符串写入文件仍然会让读者分心。
另外一种更加巧妙的方法是借助 knitr 中的 cat 引擎。该引擎为读者提供了一种在代码块中呈现文本内容或将其写入外部文件的方法,并且无需考虑有关 R 字符串的规则(例如,读者需要使用双反斜杠,才能输出反斜杠)。
要将代码块内容写入文件,只需在代码块选项 engine.opts 中指定文件路径,例如 engine.opts = list(file = 'path/to/file')。此时,engine.opts 中指定的对象将传递给 base::cat()。
接下来,将提供三个示例来说明 cat 引擎的用法。
6.3.5.1 写入 CSS 文件
第一种方法是在 R Markdown 文档中嵌入一个 css 代码块,以使用 CSS 样式化元素。
另一种方法是通过一些 R Markdown 输出格式(如,html_document)的 CSS 选项为 Pandoc 提供一个定制的 CSS 文件。 cat 引擎可以用来从 Rmd 编写这个 CSS 文件。
下面的例子展示了如何从文档中的代码块生成 custom.css 文件,并将文件路径传递给 html_document 格式的 css 选项。
---
title: "从代码块中创建一个 CSS 文件"
output:
html_document:
css: custom.css
---
下面的代码块中将写入 `custom.css` 文件,它会在 Pandoc 转换期间使用。
```{cat, engine.opts = list(file = "custom.css")}
h2 {
color: blue;
}
```
## 标题会变蓝6.3.5.2 写入 LaTeX 文件
第 3.2.4.1 节介绍了 LaTeX 文档的通用结构。其中序言 (preamble) 部分常用于加载包和定制选项。R Markdown 支持在序言中插入任意 LaTeX 代码,可以用 cat 引擎将 LaTeX 代码插入 preamble.tex 文件中,并在 YAML 元数据中加载该文件。
---
title: "从代码块中创建一个 .tex 文件"
author: "Jane Doe"
classoption: twoside
output:
pdf_document:
includes:
in_header: preamble.tex
---
# 它是如何运作的
将代码块写入文件 `preamble.tex` 以定义 PDF 输出文档的页眉和页脚:
```{cat, engine.opts=list(file = 'preamble.tex')}
\usepackage{fancyhdr}
\usepackage{lipsum}
\pagestyle{fancy}
\fancyhead[CO,CE]{This is fancy header}
\fancyfoot[CO,CE]{And this is a fancy footer}
\fancyfoot[LE,RO]{\thepage}
\fancypagestyle{plain}{\pagestyle{fancy}}
```
\lipsum[1-15]
# 更多随机内容
\lipsum[16-30]注意:
cat代码块中的内容主要目的是定义 PDF 文档的页眉和页脚。如果读者还想在页脚中显示作者姓名,可以使用engine.opts = list(file = 'preamble.tex', append = TRUE)和code = sprintf('\\fancyfoot[LO,RE]{%s}', rmarkdown::metadata$author)选项将作者信息附加到另一个cat代码块中,并使用engine.opts写入到preamble.tex文件中。
6.3.5.3 写入 YAML 文件
默认情况下,cat 代码块的内容不会显示在输出文档中。如果读者需要显示该 cat 代码块的内容,则需要将代码块选项 class.source 设置为某个语言名称。此时对应内容将会被高亮显示。下面给出一个例子,该例子将 class.source 设置为 yaml 语言:
```{cat, engine.opts=list(file='demo.yml'), class.source='yaml'}
a:
aa: "something"
bb: 1
b:
aa: "something else"
bb: 2
```此时,将会输出以下内容,并生成 demo.yml 文件。
a:
aa: "something"
bb: 1
b:
aa: "something else"
bb: 26.3.6 运行 SAS 代码
R Markdown 内置了 sas 引擎运行 SAS (https://www.sas.com) 代码。用户需要确保 SAS 可执行文件位于环境变量 PATH 中,或者也可以通过块选项 engine.path 指定 SAS 可执行文件的路径,例如:engine.path = "C:\\Program Files\\SASHome\\x86\\SASFoundation\\9.3\\sas.exe"。下面是一个输出 “Hello World” 的示例:
```{sas}
data _null_;
put 'Hello, world!';
run;
```6.3.7 运行 Stata 代码
stata 引擎 可运行 Stata (https://www.stata.com) 代码。与 SAS 类似,R Markdown 会调用环境变量或 engine.path 指定的 Stata 可执行文件,例如:engine.path = "C:/Program Files (x86)/Stata15/StataSE-64.exe"。
```{stata}
sysuse auto
summarize
```knitr 内置的 stata 引擎功能有限。Doug Hemken 开发的 Statamarkdown 包 扩展了该引擎,Github 主页见 https://github.com/Hemken/Statamarkdown。
6.3.8 用渐近线 Asymptote 创建图形
渐近线 Asymptote (https://asymptote.sourceforge.io) 是一款为了绘制技术图形而设计的矢量图描述软件。
如果读者已经安装了 Asymptote,则可以使用 asy 引擎在 R Markdown 中编写并运行 Asymptote 代码。Asymptote 的安装可以参考官网 https://asymptote.sourceforge.io/。
下面给出一个简单的示例,该示例代码来自于 https://github.com/vectorgraphics/asymptote,其输出如图 6.8 所示:
```{asy, elevation, fig.cap=' 用渐近线制作的 3D 图形。', eval=eval_asy()}
import graph3;
import grid3;
import palette;
settings.prc = false;
currentprojection=orthographic(0.8,1,2);
size(500,400,IgnoreAspect);
real f(pair z) {return cos(2*pi*z.x)*sin(2*pi*z.y);}
surface s=surface(f,(-1/2,-1/2),(1/2,1/2),50,Spline);
surface S=planeproject(unitsquare3)*s;
S.colors(palette(s.map(zpart),Rainbow()));
draw(S,nolight);
draw(s,lightgray+opacity(0.7));
grid3(XYZgrid);
```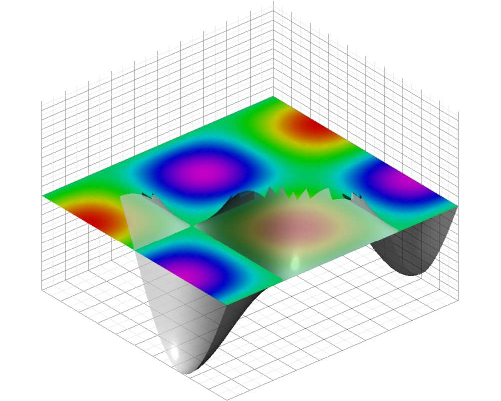
图 6.8: 用渐近线制作的 3D 图形。
上面代码块应用了选项 settings.prc = false。如果不进行此设置,当输出格式为 PDF 时,渐近线将生成交互式的 3D 图形。注意的是,想要进行图形交互(例如:使用鼠标来旋转图 6.8 ),需要使用 Acrobat Reader 软件查看。
注意: 如果读者需要输出 PDF 文件, 则可能需要安装一些额外的 LaTeX 包,否则可能会出现以下错误:
! LaTeX Error: File `ocgbase.sty' not found.这个错误是缺失了 LaTeX 包导致的,第 2.2.1.1 节介绍了解决办法。
6.3.8.1 Asymptote 读取 R 数据
下面是一个 Asymptote 使用 R 中数据的例子,首先将 R 中的数据保存到 CSV 文件中:
x = seq(0, 5, l = 100)
y = sin(x)
writeLines(paste(x, y, sep = ','), 'sine.csv')然后用 Asymptote 读取该文件,并绘制出图 6.9,对应的代码如下所示:
```{asy, sine-curve, fig.cap='将数据从 R 传递到渐近线以绘制图形', cache=TRUE, fig.width=6,fig.align='center',fig.retina=1, eval=eval_asy()}
import graph;
size(400,300,IgnoreAspect);
settings.prc = false;
// import data from csv file
file in=input("sine.csv").line().csv();
real[][] a=in.dimension(0,0);
a=transpose(a);
// generate a path
path rpath = graph(a[0],a[1]);
path lpath = (1,0)--(5,1);
// find intersection
pair pA=intersectionpoint(rpath,lpath);
// draw all
draw(rpath,red);
draw(lpath,dashed + blue);
dot("$\delta$",pA,NE);
xaxis("$x$",BottomTop,LeftTicks);
yaxis("$y$",LeftRight,RightTicks);
```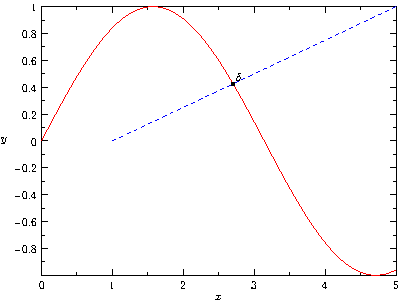
图 6.9: 将数据从 R 传递到渐近线以绘制图形
6.3.9 使用 Sass/SCSS 构建 HTML 页面
Sass (https://sass-lang.com) 是一种 CSS 扩展语言,它使用比普通 CSS 更灵活的方式创建 CSS 规则。Sass 在 CSS 的基础上引入了变量,规则,继承等更多编程特性,在语法上使用缩进而不是括号 { 分隔块,使用换行符替代分号 ; 分隔语句。下面是一个 scss 代码块:
sass (Cheng et al. 2022) 包可用于将 Sass 汇编为 CSS。基于 sass 包,knitr 包含了两个语言引擎: sass和 scss (分别对应于 Sass 和 SCSS 语法)。其功能是将代码块编译为 CSS 语言。下面给出一个由 scss 构成的代码块:
```{sass}
$font-stack: "Comic Sans MS", cursive, sans-serif
$primary-color: #0020FF
.font-demo
font: 100% $font-stack
color: $primary-color
```上面的 Scss 代码定义了两个可以复用的变量 $font-stack 和 $primary-color,并且在 .font-demo CSS 类中引用这些变量设置了字体和颜色。效果如下:
在过去的十多年间,R 语言发展的十分迅猛,这其中就包括了 R Markdown。这段往事可能要追溯到 2007 年。那时候,还在中国人民大学上学的谢益辉开始使用 Sweave,并沉迷于此无法自拔。不仅自己在写作业的时候尽可能的使用 Sweave,还持之以恒地向同学们兜售。Sweave 的命名是 S + weave,前者指的是 S 语言,这是 R 语言的前身,后者含义即“编织”。Sweave 之所以受到谢同学的追捧,正是因为它可以将某些东西编织起来——代码和代码执行后的结果。直到今天,Sweave 仍然是 RStudio 中从 Rnw 文档生成 PDF 的重要工具之一。
块选项 engine.opts 可以定制 CSS 代码的输出样式,例如:engine.opts = list(style = "expanded")。默认的样式是 “compressed”。请参阅帮助页面 ?sass::sass_options 了解更多 output_style 可用的参数。
6.4 输出钩子 (*)
第 6.2.3 节介绍了如何通过使用 knitr 包控制代码块的每一段输出,如源代码、文本输出、图像输出以及 message 等。实际上,这一控制是通过“输出钩子”(Output Hook)实现的。大部分用户不需要了解钩子函数的底层细节。有兴趣的读者可以在 https://github.com/yihui/knitr/tree/master/R 找到内置钩子函数的源代码,它们的文件名格式为 hooks-*.R,例如,hooks-md.R 包含 R Markdown 中的钩子函数)。
在 R Markdown 中,输出钩子负责将代码块的输出转换为最终文档里的视觉元素。knitr 运行完代码块后将结果存储为字符向量,钩子函数将这个字符向量加工为新的字符向量并返回到文档中,这就是用户最终看到的结果。考虑下面的代码块:
```{r}
1 + 1
```knitr 运行该段代码后,得到两个字符串:源代码 "1 + 1" 和文本输出 "[1] 2"。现在需要两个输出钩子把它们转换为输出元素,一个负责源代码,一个负责文本输出。对于源代码,R Markdown 默认调用 knitr 中 source 钩子,它的简化版如下:
# 对于上面的例子, `x` 为字符串 "1 + 1"
function(x, options) {
# 小写的 "r" 在这里表示编程语言的名称
paste(c("```r", x, "```"), collapse = "\n")
}上面的输出钩子函数将源代码转换为 Markdown 代码块,即以 ``` 开头和结尾,并添加语言标记。
类似的,处理文本输出的 output 钩子简化版如下:
function(x, options) {
paste(c('```', x, '```'), collapse = '\n')
}经过两个输出钩子的处理后,上述代码块的最终输出为:
```r
1 + 1
```
```
[1] 2
```source 和 output 的实际代码更为复杂,但背后的思想是一样的。读者可以通过在 knit_hooks 中查看钩子函数的源代码,例如:
# 为了得到有意义的输出,以下代码应在一个 knitr 文档的代码块内部执行
knitr::knit_hooks$get('source')
knitr::knit_hooks$get('output')
# 或者 knitr::knit_hooks$get(c('source', 'output'))用户可以用 knit_hooks 中的 set() 函数覆盖 R Markdown 内置的钩子,从而定制文本输出。由于该方法将覆盖现有的默认钩子,所以最好先保存默认钩子的副本,以自己的方式处理输出元素,并将结果传递给默认钩子。常见的模式为:
# 在这里使用 local() 是可选的,设置的原因只是想避免创建不必要的全局变量,如 `hook_old`)
local({
hook_old = knitr::knit_hooks$get('NAME') # 保存现有的钩子
knitr::knit_hooks$set(NAME = function(x, options) {
# 现在可以对 x 做任何处理,并将 x 传递给现有的钩子
hook_old(x, options)
})
})这里,NAME 是钩子的名称,它可以是以下值之一:
source:处理源代码;output:处理文本输出;warning:处理 warning (通常来自warning());message:处理 message (通常来自message());error:处理 error message (通常来自stop());plot:处理图像输出路径;inline:处理行内 R 表达式的输出;chunk:处理整个块的输出;document:处理整个文档的输出。
钩子的 options 参数接受一个列表,表示当前代码块的块选项。例如,如果在一个块上设置 foo = TRUE,可以通过钩子中的 options$foo 获取它的值。但需要注意的是,参数 options 对 inline 和 document 钩子不可用。
输出钩子可以让使用者能够最终控制块和文档输出的每个单独部分。与块选项(第 6.2 节,通常具有预定义的用途)相比,输出钩子可能要强大得多,因为它们是用户自定义的函数,而且可以在函数中做任何想做的事情。
6.4.1 编辑源代码
有时用户可能希望隐藏部分源代码。例如,在连接数据库时隐藏密码。第 6.2.3.1 节谈到可以使用块选项 echo 隐藏或显示某一行(例如,通过 echo = 2 可以显示第二个表达式)。本节提供了一种更加灵活的方法,它不需要指定表达式的位置或索引。
它的基本思想是在代码中添加一个特殊的注释(例如,# SECRET!!)。当在代码中检测到该注释时,将自动忽略该行。下面是使用 source 钩子的完整示例:
---
title: 用 `source` 钩子来隐藏某行代码
---
首先,设置一个 `source` 钩子来匹配并隐藏(排除)末尾处包含字符串 `# SECRET!!` 的代码行:
```{r, include=FALSE}
local({
hook_source <- knitr::knit_hooks$get('source')
knitr::knit_hooks$set(source = function(x, options) {
x <- x[!grepl('# SECRET!!$', x)]
hook_source(x, options)
})
})
```
现在可以测试这个新的钩子。在编译这个文档时,读者将看不到带有特殊注释 `# SECRET!!` 的代码行。
```{r}
1 + 1 # 正常显示代码
# 请使用你的用户名及密码
auth <- httr::authenticate("user", "passwd")
auth <- httr::authenticate("yihui", "horsebattery") # SECRET!!
httr::GET("http://httpbin.org/basic-auth/user/passwd", auth)
```上述 source 钩子的关键部分为下面这一行,它会通过 grepl() 来匹配源代码向量 x 中末尾处包含注释 # SECRET!! 的代码行,并隐藏(排除)它们:
x <- x[!grepl('# SECRET!!$', x)]准确地说,上述的钩子将隐藏(排除)所有末尾处包含注释 # SECRET!! 的 表达式,而非单独的行,因为 x 实际上是一个由 R 中表达式组成的向量。例如,对于下面的代码块:
1 + 1
if (TRUE) { # SECRET!!
1:10
}在 source 钩子中,x 的值为:
c("1 + 1", "if (TRUE) { # SECRET!!\n 1:10\n}")如果想隐藏某些特定行而非 R 代码中完整的表达式,则必须将 x 分割成单独的行。可以考虑使用函数 xfun::split_lines(),钩子函数变为:
x <- xfun::split_lines(x) # 分为单独的行
x <- x[!grepl('# SECRET!!$', x)]
x <- paste(x, collapse = '\n') # 组合成单个字符串
hook_source(x, options)第 6.4.2 节介绍了 grepl() 函数之外更多操作操作字符串的选择。
6.4.2 向源代码中添加行号
有的时候,为了方便读者阅读或讨论代码,需要给源代码添加行号。该功能可以通过自定义 source 钩子实现。例如,对于下面代码块:
```{r}
if (TRUE) {
x <- 1:10
x + 1
}
```希望得到的输出为:
if (TRUE) { # 1
x <- 1:10 # 2
x + 1 # 3
} # 4实现这个功能的 source 钩子定义如下:
---
title: 向源代码中添加行号
---
本例设置了一个 `source` 钩子来向源代码中添加行号,行号会出现在每行末尾的注释中。
```{r, include=FALSE}
local({
hook_source <- knitr::knit_hooks$get('source')
knitr::knit_hooks$set(source = function(x, options) {
x <- xfun::split_lines(x)
n <- nchar(x, 'width')
i <- seq_along(x) # 行号
n <- n + nchar(i)
s <- knitr:::v_spaces(max(n) - n)
x <- paste(x, s, ' # ', i, sep = '', collapse = '\n')
hook_source(x, options)
})
})
```
现在可以测试这个新钩子了。编译此文档时,将在每行末尾的注释中看到行号:
```{r}
if (TRUE) {
x <- 1:10
x + 1
}
```上面这个例子中使用的主要技巧是确定每行注释之前需要的空格数,以便注释可以在右边对齐。该空格数取决于每行代码的宽度,本节将钩子函数中的代码留给读者来理解。需要注意的是,函数 knitr:::v_spaces() 用于生成指定长度的空格,例如:
knitr:::v_spaces(c(1, 3, 6, 0))## [1] " " " " " " ""在实际中,如果想要在源代码或文本输出中添加行号的话,直接在块选项部分添加attr.source = ".numberLines" 或 attr.output = ".numberLines" 来实现,该语法更简洁,并且适用于源代码和文本输出块。本节中介绍 source 钩子的主要目的是展示一种使用自定义函数操作源代码的可能性。
6.4.3 为长文本添加滚动条
在通过 HTML 进行展示的时候,当代码块或者文本输出过长时,可以对其添加滚动条。第 3.1.2.7节展示了如何通过 CSS 来实现上述功能。一个更简单的方法时使用块选项的 attr.source 和 attr.output 来将 style 属性添加 Markdown 输出中的分离代码块中(有关这些选项的更多信息,请参阅第 6.2.6 节)。例如,对于这个带有 attr.output 选项的代码块:
```{r, attr.output='style="max-height: 100px;"'}
1:300
```它的 Markdown 输出为:
```r
1:300
```
```{style="max-height: 100px;"}
## [1] 1 2 3 4 5 6 7 8 9 10
## [11] 11 12 13 14 15 16 17 18 19 20
## ... ...
```随后文本输出块将被 Pandoc 转换为 HTML:
<pre style="max-height: 100px;">
<code>## [1] 1 2 3 4 5 6 7 8 9 10
## [11] 11 12 13 14 15 16 17 18 19 20
## ... ...</code>
</pre>更多有关 Pandoc 中分离代码块的信息,可参阅其阅读手册:https://pandoc.org/MANUAL.html#fenced-code-blocks。
attr.source 和 attr.output 选项让使用者能够指定每个代码块的最大高度,但是对应的语法有点笨拙,需要更好地理解 CSS 和 Pandoc 的 Markdown 语法。下面的例子展示如何使用自定义块选项 max.height 来自定义输出钩子,这样只需要设置块选项,如 max.height = "100px" 而非 attr.output = 'style="max-height: 100px;"'。本例只操作 options 参数,而不操作 x 参数:
---
title: 可滚动的代码块
output:
html_document:
highlight: tango
---
本例设置了一个输出钩子,可以当块选项 `max.height` 已被设置时,向文本输出添加 `style` 属性:
```{r, include=FALSE}
options(width = 60)
local({
hook_output <- knitr::knit_hooks$get('output')
knitr::knit_hooks$set(output = function(x, options) {
if (!is.null(options$max.height)) options$attr.output <- c(
options$attr.output,
sprintf('style="max-height: %s;"', options$max.height)
)
hook_output(x, options)
})
})
```
如果没有 `max.height`,可以看到完整的输出,即:
```{r}
1:100
```
现在设置 `max.height` 为 `100px`,这样可以在文本输出中看到一个滚动条,因为它的高度大于 100px。
```{r, max.height='100px'}
1:100
```
本质上,`max.height` 选项被转换为 `attr.output` 选项,并且即 `attr.output` 选项是存在的,这一转换也是有效的,也就是说,它不会覆盖 `attr.output` 选项,例如,可以通过 `.numberLines` 属性在文本输出的左侧显示行号:
```{r, max.height='100px', attr.output='.numberLines'}
1:100
```图 6.10 展示了代码的输出结果。需要注意的是,在最后一个代码块中使用块选项 attr.output 时,该选项将不会被 max.height 覆盖,因为这里将现有的属性与 max.height 生成的 style 属性组合在了一起:
options$attr.output <- c(
options$attr.output,
sprintf('style="max-height: %s;"', options$max.height)
)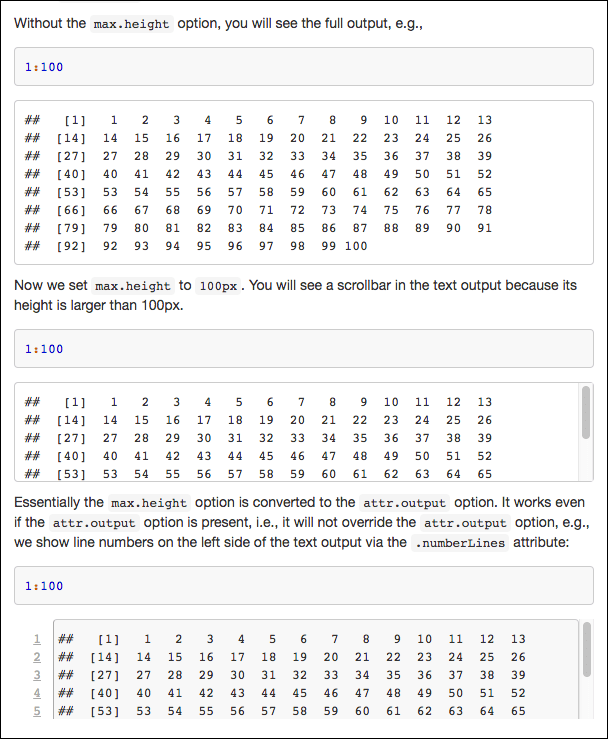
图 6.10: 一个可滚动文本输出的例子,其高度通过块选项max.height来给定
同样地,source 钩子中也可以使用相似的技巧来限制源代码块的高度。
6.4.4 截断文本输出
增加长文本可读性的另一个方法是限制最大显示行数。下面的例子通过输出钩子定义了块选项 out.lines 来限制文本输出的最大行数:
# 保存内置的 output 钩子
hook_output = knitr::knit_hooks$get("output")
# 设置一个新的 output 钩子来截断文本输出
knitr::knit_hooks$set(output = function(x, options) {
if (!is.null(n <- options$out.lines)) {
x = xfun::split_lines(x)
if (length(x) > n) {
# 截断文本输出
x = c(head(x, n), '....\n')
}
x = paste(x, collapse = '\n')
}
hook_output(x, options)
})上述钩子函数的基本思想是,如果文本输出的行数大于块选项 out.lines 设置的阈值(存储在变量 n 中),只保留前 n 行,并添加省略号(....)来表示输出被截断。
现在可以通过设置块选项 out.lines = 4 来测试新的输出钩子,读者将会看到四行输出:
print(cars)## speed dist
## 1 4 2
## 2 4 10
## 3 7 4
....由于已经将原始的输出钩子存储在 output 中,故可以通过再次调用 set() 来恢复它:
knitr::knit_hooks$set(output = hook_output)作为进一步的练习,可以尝试以不同的方式截断输出:给定块选项’ out.lines 来确定最大行数,能在中间而不是末尾截断输出吗?例如,如果设定 out.lines = 10,提取前 5 行和后 5 行,并在中间添加 .... 的输出是这样的:
## speed dist
## 1 4 2
## 2 4 10
## 3 7 4
## 4 7 22
....
## 46 24 70
## 47 24 92
## 48 24 93
## 49 24 120
## 50 25 85需要注意的是,输出的最后一行(即钩子函数的参数 x)可能是空行,所以可能需要设定 c(head(x, n/2), '....', tail(x, n/2 + 1)),其中 + 1 将最后的空行也纳入考虑。
6.4.5 以 HTML5 格式输出图像
默认情况下,R Markdown 的 HTML 输出中的图包含在标签 <p> 或 <div> 下的 <img src="..." /> 中,但很多时候使用者可能想输出以 HTML531 格式来输出图像。
下面的例子展示了如何使用 HTML5 的标签 <figure> 来显示图像。
---
title: 在标签 `<figure>` 中输出图像
output: html_document
---
在块选项 `options$fig.cap` 中给定图像文件路径 `x` 和图像标题(caption),希望使用如下形式把图像写入 HTML5 的标签之中:
```html
<figure>
<img src="PATH" alt="CAPTION" />
<figcaption>CAPTION</figcaption>
</figure>
```
现在重新定义 `plot` 钩子(仅当输出格式为 HTML 时):
```{r}
if (knitr::is_html_output()) knitr::knit_hooks$set(
plot = function(x, options) {
cap <- options$fig.cap # 图像标题
tags <- htmltools::tags
as.character(tags$figure(
tags$img(src = x, alt = cap),
tags$figcaption(cap)
))
}
)
```
代码块中的图像将被放置在 `<figure>` 标签之中:
```{r, fig.cap='一个`cars`数据的散点图'}
par(mar = c(4.5, 4.5, .2, .2))
plot(cars, pch = 19, col = 'red')
```
可以进一步添加一些 CSS 样式来让 `<figure>` 和 `<figcaption>` 标签“看”起来更好一些(`figure` 有虚线边框,图像标题有浅粉色背景):
```{css, echo=FALSE}
figure {
border: 2px dashed red;
margin: 1em 0;
}
figcaption {
padding: .5em;
background: lightpink;
font-size: 1.3em;
font-variant: small-caps;
}
```图像的输出如图 6.11 所示。注意,这个例子实际上覆盖了默认的 plot 钩子,而本节的大多数其他例子都是在默认钩子的基础上构建自定义钩子。只有当确定要忽略默认钩子的一些内置特性时,才应该完全覆盖默认钩子。例如,在本例中,plot 钩子函数没有考虑像 out.width = '100%' 或 fig.show = 'animate' 这样的块选项。
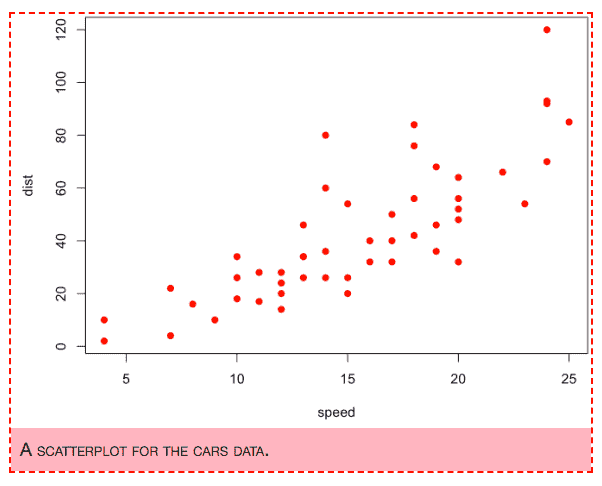
图 6.11: 一个在HTML5 figure 标签中的图像
上例展示了在 plot 钩子 中使用图像文件路径 x 可以进行的操作。如果所需要的只是自定义图像的样式,则不必使用 HTML5 标签。通常情况下,默认的 plot 钩子会以如下的 HTML 代码输出图像:
<div class="figure">
<img src="PATH" />
<p class="caption">CAPTION</p>
</div>所以可以仅为 div.figure 和 p.caption 定义 CSS 规则。
6.5 缓存 (*)
6.5.1 缓存耗时的代码块
在一个报告中,往往会有一些运行起来很费时且很关键的代码块(如数据预处理等)。为了节省时间,可以考虑通过块选项 cache = TRUE 来缓存该代码块的结果。当启用缓存时,如果一个代码块之前被执行过且之后没有任何变化时,knitr 将跳过这个代码块的执行,从而大大缩短编译所需的时间。而当再次修改代码块时(如修改代码或块选项),之前的缓存将自动失效,并且 knitr 将再次运行并缓存该代码块。
对于一个被缓存了的代码块,它的输出以及变量对象将从上一次的运行中自动加载,就像该代码块被再次执行了一样。当加载结果比计算结果快得多时,缓存操作通常是有用的。然而,天下没有免费的午餐,有的时候 knitr 会令缓存失效或是部分失效,如外部文件内容的改变可能没有体现在报告中等等。更多关于如何缓存,特别是缓存失效的相关知识可参见:https://yihui.org/en/2018/06/cache-invalidation/。
缓存的一个典型应用场景是保存和重新加载那些需要很长时间才能在代码块中计算的 R 对象。需要注意的是,代码需要没有任何“副产物”,否则建议不要进行缓存。例如在使用 options() 更改全局 R 选项时,产生的更改不会被缓存。
正如前文提到的,缓存依赖于代码或块选项。如果改变了任何块选项(除了 include 选项),缓存将会失效。此特性可用于解决一个常见的问题,即当代码需要读取外部数据文件时,应在更新数据文件时使缓存失效,那仅仅像下面这样简单地使用 cache = TRUE 是不够的:
```{r import-data, cache=TRUE}
d <- read.csv('数据.csv')
```必须要让 knitr 知道数据文件是否已被更改。一种方法是添加另一个块选项 cache.extra = file.mtime('数据.csv'),或者更严格的方式:cache.extra = tools::md5sum('数据.csv')。前者意味着如果文件的修改时间发生了变化,就需要使缓存失效;而后者的意思是,如果文件的内容被修改,就更新缓存。需要注意的是,cache.extra不是一个内置的 knitr 代码选项,可以为该选项使用任何其他名称,只要它不与内置选项名称冲突。
类似地,还可以将缓存与其他信息相关联,比如R的版本(cache.extra = getRversion())、时间(cache.extra = Sys.Date())或是操作系统(cache.extra = Sys.info()[['sysname']]),当这些条件改变时,可以使缓存正确地失效。
需要注意的是,本书不建议在文档中设置全局块选项 cache = TRUE,因为缓存可能相当棘手。相反的,可以只在个别耗时很久的代码块上启用缓存,这样并不会产生副产物。
如果对 knitr 的缓存设计不满意,还可以选择自己缓存对象,下面是一个简单的例子:
if (file.exists('结果.rds')) {
res = readRDS('结果.rds')
} else {
res = compute_it() # 一个很耗时的函数
saveRDS(res, '结果.rds')
}在这一例子中,使缓存失效的唯一(也是简单的)方法就是删除文件results.rds。如果对这个简单的缓存机制感兴趣,可以使用在6.5.4节中介绍的函数xfun::cache_rds()。
6.5.2 为多种输出格式缓存代码块
当通过块选项 cache = TRUE启用缓存时,knitr 将把在代码块中生成的 R 对象写入缓存数据库,以便下次重新加载它们。缓存数据库的路径由块选项 cache.path 决定。默认情况下,R Markdown 对不同的输出格式会使用不同的缓存路径,这意味着对于每种输出格式都将完全执行一次这个(耗时的)代码块。这可能很不方便,但这种默认的行为是有原因的,即代码块的输出可能依赖于特定的输出格式。例如,生成图像,当输出格式为word_document时,图像的输出可能是像  这样的标记代码;而或者当输出格式为 html_document 时,输出的HTML代码则类似 <img src="path/to/image.png" />。
当代码块没有任何副产物(如图像)时,对所有输出格式使用相同的缓存数据库是安全的,还可以节省时间。例如,当读取一个大型数据对象或运行一个比较耗时的模型时,若结果不依赖于输出格式,就可以使用相同的缓存数据库。可以通过块选项 cache.path ,例如:
```{r important-computing, cache=TRUE, cache.path="cache/"}
```实际上,在 R Markdown 中,cache.path 的默认设置为 cache.path = "INPUT_cache/FORMAT/",其中 INPUT 代表输入的文件名,FORMAT 为输出格式(如 html、latex 或 docx),这就导致了不同的输出格式对应不同的缓存路径。
6.5.3 缓存大型的对象
当设定块选项 cache = TRUE 时,缓存的对象将被延迟加载到 R 中,这意味着对象将不会从缓存数据库中读取,直到它在代码中被实际使用。当不是所有对象都在文档中稍后被使用时,这一操作可以节省一些内存。例如,如果读取了一个大型的数据对象,但在后续的分析中只使用了其中的一个子集,那么原始的数据对象将不会从缓存数据库中加载:
```{r, read-data, cache=TRUE}
full <- read.csv("大型数据集.csv")
rows <- subset(full, price > 100)
# 之后只使用 `rows` 数据集
```
```{r}
plot(rows)
```然而,当一个对象太大时,可能会遇到这样的报错:
Error in lazyLoadDBinsertVariable(vars[i], ...
long vectors not supported yet: ...
Execution halted如果出现这个问题,可以尝试通过块选项 cache.lazy = FALSE 来关闭延迟加载,这样该代码块中的所有对象都将立即被加载到内存中。
6.5.4 基于 cache_rds() 的缓存
如果在使用的过程中,觉得前文介绍的基于 knitr 的缓存机过于复杂,可以考虑使用基于函数 xfun::cache_rds() 的一个更简单的缓存机制,例如:
xfun::cache_rds({
# 在这里编写耗时的代码
})关于 knitr 缓存,其棘手之处在于如何决定何时使缓存失效,而使用 xfun::cache_rds() 则要清楚得多:第一次将 R 表达式传递给这个函数时,它会计算表达式并将结果保存到 .rds 文件中;下次再次运行 cache_rds() 时,它会读取 .rds 文件,并立即返回结果,而不再次计算表达式。使缓存无效的最明显的方法是删除 .rds 的文件。如果不想手动删除它,则可以用参数 rerun = TRUE 来调用 xfun::cache_rds()。
当 xfun::cache_rds() 在 knitr 源文档的一个代码块中被调用时,.rds 文件的路径由块选项 cache.path 和块标签决定。例如,对于在 Rmd 文档 input.Rmd 中带有块标签 foo 的代码块:
```{r, foo}
res <- xfun::cache_rds({
Sys.sleep(3)
1:10
})
```.rds 文件的路径格式为 input_cache/FORMAT/foo_HASH.rds,其中 FORMAT 是 Pandoc 输出格式名称(例如 html 或 latex), HASH 是一个MD5哈希值,包含了 32 个十六进制数字(a-f 和 0-9),例如 input_cache/html/foo_7a3f22c4309d400eff95de0e8bddac71.rds。
如帮助页面 ?xfun::cache_rds 所述,通常在两种的情况下可能想要使缓存失效:(1)待求值表达式中的代码发生了变化;(2)代码使用了一个外部变量,并且该变量的值已经改变。本节接下来将解释这两种情况下缓存是如何失效的,以及如何将缓存的多个副本保存到对应于不同版本的代码中。
6.5.4.1 使缓存失效
cache_rds() 中的内容改变时(例如,从 cache_rds({x + 1}) 改为 cache_rds({x + 2})),缓存将自动失效,表达式将被重新计算。但是需要注意的是,空格或注释的变化是不重要的,或者一般来说,只要更改不影响已解析的表达式,缓存就不会失效。例如,下面传递给 cache_rds() 的两个表达式在本质上是相同的:
res <- xfun::cache_rds({
Sys.sleep(3);
x<-1:10; # 分号不影响
x+1;
})
res <- xfun::cache_rds({
Sys.sleep(3)
x <- 1:10 # 一个注释
x +
1 # 可以随意修改空格部分
})因此,如果对第一个表达式执行 cache_rds() ,那么第二个表达式将能够调用缓存的结果。这一特性非常有用,因为其允许在代码中进行修饰性更改,而不会使缓存失效。
如果不确定两个版本的代码是否相等,则可以尝试下面的 parse_code() 函数:
parse_code <- function(expr) {
deparse(substitute(expr))
}
# 空格或分号不影响
parse_code({x+1})## [1] "{" " x + 1" "}"parse_code({ x + 1; })## [1] "{" " x + 1" "}"# 左箭头和右箭头是等价的
identical(parse_code({x <- 1}), parse_code({1 -> x}))## [1] TRUE通常情况下,表达式中有两种类型的变量:全局变量和局部变量。全局变量是在表达式外部创建的,局部变量则是在表达式内部创建的。如果表达式中全局变量的值发生了变化,那么缓存的结果和再次运行的结果之间可能会产生差异。例如,在下面的表达式中,y 相对于 cache_rds 是全局变量:
y <- 2
res <- xfun::cache_rds({
x <- 1:10
x + y
})cache_rds() 不能自动检测发生在全局变量上的变化。如果想要在 y 变化时重新计算 res,需要显示声明 y 作为表达式的依赖项。hash 参数接受一个列表作为表达式的依赖项:
res <- xfun::cache_rds({
x <- 1:10
x + y
}, hash = list(y))knitr 用哈希记值记录列表中每个元素的状态以及它们是否被改变。当 hash 中的任意值改变时,对应的哈希值发生变化,knitr 于是知道应该让缓存失效。例如,如果想要使缓存依赖于 y 以及 R 的版本,可以这样指定依赖:
res <- xfun::cache_rds({
x <- 1:10
x + y
}, hash = list(y, getRversion()))或者如果想让缓存依赖于 y 以及数据文件最后一次修改的时间,可以这样做:
res <- xfun::cache_rds({
x <- read.csv("数据.csv")
x[[1]] + y
}, hash = list(y, file.mtime("数据.csv")))如果不想为 hash 参数提供全局变量的列表,则可以尝试 hash = "auto",它将使 cache_rds() 自动找出所有的全局变量,并将它们作为 hash 参数的值,例如:
res <- xfun::cache_rds({
x <- 1:10
x + y + z # y 和 z 是全局变量
}, hash = "auto")这等价于:
res <- xfun::cache_rds({
x <- 1:10
x + y + z # y 和 z 是全局变量
}, hash = list(y = y, z = z))当 hash = "auto" 时,全局变量由 codetools::findGlobals() 识别,这可能不是完全可靠的,所以如果需要完全确定哪些变量可以使缓存失效,本书建议在 hash 参数中显示给定依赖列表。
6.5.4.2 保留缓存的多个副本
由于缓存通常用于非常耗时的代码,在使其失效时应当保守一些。有的时候可能会因过早或主动地使缓存失效而后悔,因为如果再次需要一个旧版本的缓存时,则将不得不等待很长的时间才能重新完成计算。
若将 cache_rds() 中的 clean 参数设置为 FALSE,则将允许保留旧的缓存副本。也可以设置全局 R 选项 options(xfun.cache_rds.clean = FALSE) 来使其成为文档的默认行为。在默认情况下,clean = TRUE 和 cache_rds() 每次都会尝试删除旧的缓存。如果还在进行代码测试,那么设置 clean = FALSE 会很有用。例如,可以缓存一个线性模型的两个版本:
model <- xfun::cache_rds({
lm(dist ~ speed, data = cars)
}, clean = FALSE)
model <- xfun::cache_rds({
lm(dist ~ speed + I(speed^2), data = cars)
}, clean = FALSE)在决定使用哪个模型之后,可以再次设置 clean = TRUE,或者删除 clean 参数(默认为 TRUE)。
6.5.4.3 与 knitr 的缓存比较
那么什么时候使用 knitr 的缓存(例如,设置块选项 cache = TRUE),什么时候在 knitr 源文档中使用 xfun::cache_rds()呢?后者最大的缺点是它不缓存副产物(而只缓存表达式的值),而 knitr 却可以。有的时候,一些副产物是有用的,比如打印的输出或图像。例如,在下面的代码中,当使用 cache_rds() 加载缓存时,文本输出和图像将会丢失,只会返回 1:10:
xfun::cache_rds({
print("Hello world!")
plot(cars)
1:10
})相比之下,对于设定选项为 cache = TRUE 的代码块,所有的内容都将被缓存:
```{r, cache=TRUE}
print("Hello world!")
plot(cars)
1:10
```但 knitr 的缓存最大的缺点是缓存可能会在不经意间失效,因为影响 knitr 判断是否应该重新计算的因素很多。例如,任何代码块块选项的改变都会使缓存失效32,但有些块选项可能与计算无关。例如在下面的代码块中,改变块选项 fig.width = 6 到 fig.width = 10 不会影响结果,因为该代码块并不涉及生成图片,但在 knitr 眼中这个代码块的缓存已经过期了,需要重新运行。
```{r, cache=TRUE, fig.width=6}
# 这个块没有生成图像
x <- rnorm(1000)
mean(x)
```另外一个对比是,xfun::cache_rds() 是缓存计算结果的通用方法,它可以在任何地方使用,而 knitr 的缓存只能在 knitr 文档中使用。
6.6 其它使用 knitr 的小技巧 (*)
除了块选项(第 6.2 节)和输出钩子(第 6.4 节)之外,在 knitr 中还有很多有用的函数和技巧。本节将介绍这些技巧,例如重复使用代码块(第 6.6.1 节)、提前退出编译(第 6.6.3 节)、生成一个图像并在其他地方显示(第 6.6.4 节)等等。
6.6.1 重复使用代码块
有的时候,使用者需要在源文档中重复使用某些代码块,例如在详细讲解某一段代码、重复生成一些数据或者需要在附录中呈现所有代码时。这当然可以通过复制粘贴实现,但通常会很麻烦,甚至会在改一段代码时忘记修改对应的另一段代码。实际上,还有更简便的方法实现重复使用代码块的功能,这其中的关键点在于标记代码块,从而在其它地方用标签的形式引用它们。本节将介绍三种重复使用代码块的方法。
6.6.1.1 嵌入代码块 (*)
R Markdown 支持在 R 函数中使用 << label >> 作为占位符,随后以 label 为标签的代码块中的内容会被嵌入该函数中。例如,可以这样创建一个 R 函数:
F2C <- function(x) {
<<check-arg>>
<<convert>>
}随后,分别用两个标签为 check-arg 和 convert 的代码块实现 F2C 函数的功能:
首先,检查输入值是否为数字:
```{r, check-arg, eval=FALSE}
if (!is.numeric(x)) stop("The input must be numeric!")
```
然后进行转换:
```{r, convert, eval=FALSE}
(x - 32) * 5/ 9
```编译时,knitr 将自动将 <<check-arg>> 和 <<convert>> 扩展为 check-arg 和 convert 两个代码块的内容,生成:
F2C <- function(x) {
if (!is.numeric(x)) stop("The input must be numeric!")
(x - 32) * 5/ 9
}这是唐纳德·克努特(Donald Knuth)提出的文学编程中的主要思想之一。这种技术的优点在于,使用者可以将(复杂的)代码分割成更小的部分,将每个部分写入单独的代码块中,并使用文字叙述来解释它们。所有的部分都可以被放入要执行的主代码块中。
一个代码块中可以嵌入任意数量的其他代码块,并且嵌入也可以是递归的。例如,可以将块 A 嵌入到块 B 中,将块 B 嵌入到块 C 中,这样块 C 将借由块 B 包含块 A 中的代码。
另外,标记符 <<label>> 不必单独写成一行,它可以嵌入到代码块的任何地方。
6.6.1.2 在另一个块中使用相同的块标签
如果想要重复多次使用完全相同的代码块,则可以用一个标签来定义块,并使用相同的标签创建更多的代码块,但需要保留块的内容为空,例如:
下面是一个没有被运行的代码块:
```{r, chunk-one, eval=FALSE}
1 + 1
2 + 2
```
现在运行该代码块:
```{r, chunk-one, eval=TRUE}
```上面的例子使用了两次块标签 chunk-one,第二个块只是重复使用了第一个块的代码。
但是最好不要多次(多于一次)使用此方法多次运行代码块来生成图像或其他文件,因为从后面的块创建的图像文件可能会覆盖前一个块创建的文件。如果只有一个块使用块选项 eval = TRUE,而所有其他块使用 eval = FALSE 的话是可以的。
6.6.1.3 引用代码块标签 (*)
除了块之间的嵌入以及使用块标签外,还可以通过引用标签的方法来重复使用代码块。该方法的核心在于块选项 ref.label,该选项利用一个由块标签组成的向量来检索这些块的内容。例如在下例中,标签为 chunk-a 的代码块是 chunk-c 和 chunk-b 的组合:
```{r chunk-a, ref.label=c('chunk-c', 'chunk-b')}
```
```{r chunk-b}
# 这是块 b
1 + 1
```
```{r chunk-c}
# 这是块 c
2 + 2
```chunk-a 的内容在编译时被替换为:
```{r chunk-a}
# 这是块 c
2 + 2
# 这是块 b
1 + 1
```ref.label 提供了一种在文档中灵活组织代码块的方法,而无需复制粘贴。需要注意的是,被引用的代码块在使用 ref.label 的代码块之前还是之后并不重要,文档中出现在前的代码块同样引用后面的代码块。
6.6.2 在创建对象之前使用它 (*)
一个 knitr 文档中的所有代码,包括代码块和行内 R 表达式中的代码,从开始到结束都是按先后顺序执行的。从理论上讲,在给变量赋值之前不能使用它。但是,在某些情况下,使用者可能需要在文档前面提到一个变量的值。例如,通常在文章的摘要中需要显示结果,但结果实际上是在文档的后面计算的。下面的例子说明了这个想法,但无法编译:
---
题目:一个重要的报告
摘要: >
在本文的分析中,`x` 的平均值是 `r knitr::inline_expr('mx')`...
---
在下面的块中创建对象 `mx`:
```{r}
x <- 1:100
mx <- mean(x)
```要解决这个问题,对象的值必须先保存在某个地方,并在下一次编译文档时加载。需要注意的是,这一操作意味着文档至少需要被编译两次。下面的例子介绍了一种可能的解决方案,即使用 saveRDS() 函数:
```{r, include=FALSE}
mx <- if (file.exists('mean.rds')) {
readRDS('mean.rds')
} else {
"The value of `mx` is not available yet"
}
```
---
题目:一个重要的报告
摘要: >
在本文的分析中,`x` 的平均值是
`r knitr::inline_expr('mx')`...
---
在下面的块中创建对象 `mx`:
```{r}
x <- 1:100
mx <- mean(x)
saveRDS(mx, 'mean.rds')
```第一次编译本文档时,将会在摘要中看到短语 “The value of mx is not available yet”。之后当再次编译它时,将会看到 mx 的值。
函数 knitr::load_cache() 是一个替代的解决方案,它允许在特定的代码块已经被缓存了之后从该代码块加载对象的值。这个想法与上面的例子类似,但它将减少手动保存和加载对象的工作,因为对象会自动保存到缓存数据库,只需要通过 load_cache() 加载它即可,例如:
---
题目:一个重要的报告
摘要: >
在本文的分析中,`x` 的平均值是
`r knitr::inline_expr("knitr::load_cache('mean-x', 'mx')")`.
---
在下面的块中创建对象 `mx`:
```{r mean-x, cache=TRUE}
x <- 1:100
mx <- mean(x)
```这个例子中,R 代码块被添加了一个块标签 mean-x(被传递给 load_cache() 函数),并通过块选项 cache = TRUE 来缓存它。此代码块中的所有对象都将被保存到缓存数据库中。同样的,必须至少编译该文档两次,这样才能正确地从缓存数据库加载对象 mx。如果 mx 的值今后不会被更改,则不需要再次编译该文档。
如果在 load_cache() 的第二个参数中没有指定对象名,整个缓存数据库都将被加载到当前环境中。然后,可以从缓存数据库中调用这些本应在后续的文档中被创建的对象,例如:
knitr::load_cache('mean-x')
x # 对象 `x`
mx # 对象 `mx`6.6.3 提前退出编译
有的时候,使用者可能需要提前退出编译,而不是在文档的末尾退出。例如,可能只希望分享结果的前半部分,或者可能文档末尾的一些代码尚未完成。在这些情况下,可以考虑在一个代码块中使用 knit_exit() 函数,它将在该代码块之后结束编译过程。
下面的例子先给出了一个非常简单的块,并紧跟着有一个更耗时的块:
```{r}
1 + 1
knitr::knit_exit()
```
在输出中将只会看到上面的内容。
```{r}
Sys.sleep(100)
```一般情况下,需要等待 100 秒来编译整个文档,但由于调用了 knit_exit(),文档的剩余部分将不会被编译。
6.6.4 控制图像显示位置
通常情况下,由代码块中生成的图像会显示在代码块下面,但也可以让它显示在任意位置,例如:
在这个代码块中生成了一个图像,但是没有显示出来:
```{r cars-plot, dev='png', fig.show='hide'}
plot(cars)
```
随后,作者可以在文档的任意后续部分引用该图像:
")`)上述代码块使用了块选项 fig.show='hide' 来把图像暂时隐藏起来。然后在另一段中,通过函数 knitr::fig_chunk() 得到该文件的路径,例如 test_files/figure-html/cars-plot-1.png。使用者需要将块标签和图像设备名称传递给 fig_chunk(),以便它更好地得到图像文件路径。
https://stackoverflow.com/a/46305297/559676 介绍了 fig_chunk() 在 blogdown 网站中的应用。这个函数适用于任何 R Markdown 的输出格式,并且它对于在幻灯片上显示图像特别有用,因为幻灯片页上的屏幕空间通常是有限的,可以在一张幻灯片上展示代码,然后在另一张幻灯片上展示图像。
6.6.5 修改之前代码块中的图像
默认设置下,对每个代码块生成的图像,knitr 都会启用一个新的图像设备。这就带来了一个问题:不能轻易地修改之前代码块产生的图像,因为之前的图像设备已经关闭了。这个问题对于 base R 生成的图形最为显著,但一般不会影响从基于 grid 网格系统生成的图像 (例如 ggplot2),因为其可以被保存为 R 对象。例如,base R 作图常涉及先创建一个基础图形,随后用 points() 和 lines() 等函数在基础图形上叠加图形元素。但是这些函数在 knitr 中无法访问到先前已经被关闭的图像设备。一个解决办法是让 knitr 保持打开同一个图像设备,可以在设置 knitr 选项 global.device `:
knitr::opts_knit$set(global.device = TRUE)需要注意的是,这里使用的是 opts_knit 而非更常用的 opts_chunk。相关例子可参见 https://stackoverflow.com/q/17502050。下面是一个完整的例子:
---
title: "使用全局图像设备记录图像"
---
首先,开启全局图像设备:
```{r, include=FALSE}
knitr::opts_knit$set(global.device = TRUE)
```
画一张图:
```{r}
par(mar = c(4, 4, 0.1, 0.1))
plot(cars)
```
给之前代码块生成的图添加一条线:
```{r}
fit <- lm(dist ~ speed, data = cars)
abline(fit)
```
不再使用全局图像设备了:
```{r, include=FALSE}
knitr::opts_knit$set(global.device = FALSE)
```
画另一张图:
```{r}
plot(pressure, type = 'b')
```6.6.6 复用块选项 (*)
使用者有时需要经常使用一些块选项,例如对一些图像的设置、对一些结果输出方式的设置。这当然可以通过复制粘贴实现,但不妨把它们保存为一个组,然后只使用组的名称来重复使用它们。这可以通过 knitr::opts_template$set(name = list(options)) 来实现,之后可以使用 opts.label 来引用组名,从而实现重复使用。例如:
```{r, setup, include=FALSE}
knitr::opts_template$set(fullwidth = list(
fig.width = 10, fig.height = 6,
fig.retina = 2, out.width = '100%'
))
```
```{r, opts.label='fullwidth'}
plot(cars)
```在设定 opts.label = 'fullwidth' 时, knitr 将从 knitr::opts_template 中读取块选项,并将它们应用到当前的块中,这样可以节省一些打字的工作量。如果一个块选项要在文档中全局使用,则应该考虑全局地设置它(参见第 6.2 节)。
另外,还可以覆盖从 opts.label 中读取的选项,例如,如果在下面的块中设置 fig.height = 7,则实际的 fig.height 将变为 7 而非 6,从而可以对单个块进行调整:
```{r, opts.label='fullwidth', fig.height=7}
plot(cars)
```事实上,可以保存任意数量的分组选项,例如 knitr::opts_template$set(group1 = list(...), group2 = list(...))。
6.6.7 使用 knitr::knit_expand() 来生成 Rmd 源代码
函数 knitr::knit_expand()可以将 {{ }} 中的表达式“扩展”为它的值(默认),例如,
knitr::knit_expand(text = "`pi` 的值是 {{pi}}.")
## [1] "`pi` 的值是 3.14159265358979."
knitr::knit_expand(
text = "`a` 的值是 {{a}}, 所以 `a + 1` 是 {{a+1}}.",
a = round(rnorm(1), 4)
)
## [1] "`a` 的值是 -0.7558, 所以 `a + 1` 是 0.2442."这意味着,如果有一个 R Markdown 文档,其中包含了 {{ }} 中的一些动态部分,那么可以在该文档上应用 knit_expand(),然后调用 knit() 来编译它。例如,下面是一个名为 template.Rmd 的模板文档:
# 在 {{i}} 上进行回归
```{r lm-{{i}}}
lm(mpg ~ {{i}}, data = mtcars)
```可以用 mpg 来对 mtcars 数据集中的所有其他变量逐个建立线性回归模型:
```{r, echo=FALSE, results='asis'}
src = lapply(setdiff(names(mtcars), 'mpg'), function(i) {
knitr::knit_expand('template.Rmd')
})
res = knitr::knit_child(text = unlist(src), quiet = TRUE)
cat(res, sep = '\n')
```如果理解这个例子有难度,可参阅第 6.2.3.4 节,以了解块选项 results = 'asis',以及第 7.1.4 节来了解 knitr::knit_child() 的用法。
6.6.8 重复代码块标签 (*)
默认情况下,knitr 不允许在文档中重复代码块标签。在编译文档时,重复的标签将导致错误。这种情况常见于在文档中复制和粘贴代码块的时候,会产生这样的错误信息:
processing file: myfile.Rmd
Error in parse_block(g[-1], g[1], params.src, markdown_mode) :
Duplicate chunk label 'cars'
Calls: <Anonymous> ... process_file -> split_file -> lapply ->
FUN -> parse_block
Execution halted然而,在某些情况下,使用者会希望允许标签可以重复。例如,如果有一个母文档 parent.Rmd,在其中会多次编译子文档,下面的代码会运行失败:
# 设置
settings = list(...)
# 第一次运行
knit_child('useful_analysis.Rmd')
# 重新设置
settings = list(...)
# 再次运行
knit_child('useful_analysis.Rmd')在这个场景中,可以通过在编译子文档之前在 R 中设置这个全局选项来允许标签可重复:
options(knitr.duplicate.label = 'allow')如果想在母文档而不是子文档中允许标签可重复,则必须在 knitr::knit() 被调用之前设置这个选项。一种可能的方法是在 ~/.Rprofile 中设置这个选项(更多信息可参见帮助页面 ?Rprofile)。
设置此选项时需要很谨慎,与大多数的报错一样,它们的存在是有原因的。允许重复的块可能会在图像和交叉引用方面产生静默问题(silent problem)。例如,理论上,如果两个代码块具有相同的标签,并且两个代码块都生成图像,那么它们的图像文件将互相覆盖(并不会产生错误或警告消息),因为图像的文件名是由块标签决定的。使用选项 knitr.duplicate.label = "allow" 时, knitr 将通过添加数字后缀来静默地改变重复标签。例如,对于两个代码块:
```{r, test}
plot(1:10)
```
```{r, test}
plot(10:1)
```第二个标签将被静默地更改为 test-1,这将避免覆盖由标签 test 的块产生的图像,但这也使得块标签不可被预知,所以在交叉引用图像时可能会产生困难(参见 2.8.7 节),因为交叉引用也是基于块标签的。
参考文献
细心的读者可以发现,后文例子中,
_实际上被转义为了\\_,LaTeX 中大于等于号\ge也被写为了\\ge,这是因为 R 中\本身也代表转义,所以在 R 中输入文件地址时要将其替换为\\或/。↩︎层叠样式表,是一种用来表现 HTML 等文件样式的计算机语言。↩︎
如果需要支持其他输出格式,如 LaTeX 和 Word,gtsummary 包(R-gtsummary?)已经做了一些基于 gt 的扩展,可参见:https://github.com/ddsjoberg/gtsummary.↩︎
该包已停止更新,需在官网自行下载,地址:https://cran.microsoft.com/snapshot/2020-04-20/web/packages/cairoDevice/index.html。↩︎
实际工作中读者应使用 R Markdown 内置的 Python 引擎↩︎
HTML5 是 HTML 的最新标准,为原始 HTML 增加了很多功能,极大地提升了用户的使用体验。如果想更多地了解二者的差异,可以参见 https://www.hostinger.com/tutorials/difference-between-html-and-html5#HTML_vs_HTML5_-_Comparison。↩︎
这是默认的行为,也可以进行调整。如果想了解如何使缓存更精细,而非所有块选项都会影响缓存,请参阅:https://yihui.org/knitr/demo/cache/。↩︎